Software Quality and Testing Summary
Table of Contents
- Table of Contents
- Terminology
- Principles of software testing
- Test Design
- JUnit
- Testing techniques
- Boundary testing
- Variables:
- Equivalence partitioning and boundary analysis:
- Structural testing
- Strategy:
- Test cases:
- Structural testing
- Design by contracts
- Test Oracles
- Pre- and post-conditions
- Invariant
- Design by contracts
- Testing for Liskov Substitution Principle (LSP) Compliance
- Property-Based testing
- Testing Pyramid
- Test doubles
- Design for testability
- Web testing
- Javascript Unit testing
- Javascript Unit test without framework
- Javascript UI test without framework
- JavaScript unit testing (with React and Jest)
- Tests for the UI with Jest
- Jest mocks
- Snapshot testing
- End-to-end testing
- Behaviour-driven design
- Usability and accessibility testing
- Load and performance testing
- Automated visual regression testing (screenshot testing)
- SQL testing
- Test Driven Development
- Test code quality and engineering
- Security Testing
- Intelligent testing
- Mutation Testing
- Fuzz testing
- Search-based software testing
Terminology
- Failure: Manifested inability of a system to performa required function. (When a system stops working as expected)
- Defect, fault, bug: The cause of the failure in terms of code/hardware implementation.
- Error (mistake): The cause of the bug (i.e. developer negligency)
- Defect, fault, bug: The cause of the failure in terms of code/hardware implementation.
- Testing: attempt to trigger failures
- Debugging: attempt to find the failure bug (defect, fault)
- Verification: Verify that the system behaves bug free
- Validation: Validate that the system delivers the busines value it should deliver (features)
Small checks
A common technique developers use (which we will try as much as possible to convince you not to do) is that they implement the program based on the requirements, and then perform “small checks” to make sure the program works as expected. However these checks are arbitrary and often not enough.
Principles of software testing
- Testing cannot show absence of bugs:
- Abscence of evidence is not evidence of absence.
- Testing specific scenarios only ensures those scenarios behave as expected.
- Exaustive testing is impossible:
- Possible scenarios increase exponentially as features are added. In a moderately large program, it’s impossible to test them all, but since bugs are not uniformly distributed we should focus on finding the bug-prone areas.
- Testing needs to start early
- Defects tend to be clustered
- Pesticide paradox yields test methods ineffective:
- Applying the same techniques over and over yields diminishing returns as you are leaving other types of bugs untested
- There is no one silver bullet testing strategy that can guarantee a complete bug-free software. Combining different testing strategies yields a better result in finding bugs.
- Testing is context-dependent
- A mobile app needs diffferent tests than a web app
- There is more to quality than absence of defects
- Besides software verification (bug free) we need software validation to ensure business value.
Test Design
- Decide which of the inintely many possible test cases to create
- Maximize information gain
- Minimize cost
- test strategy: Systematic approach to reach test cases
- targets specific types of faults until a given adequacy criterion is achieved
- Test design begins at the start of the project
Test levels
Have different levels of granularity:
- Unit testing
- Integration testing
- System testing
- Manual
Test types
Different objectives:
- Functionality (old/new)
- Security
- Performance
- …
JUnit
The steps to create a JUnit class/test is often the following:
-
Create a Java class under the directory /src/test/java/roman/ (or whatever test directory your project structure uses). As a convention, the name of the test class is similar to the name of the class under test. For example, a class that tests the RomanNumeral class is often called RomanNumeralTest. In terms of package structure, the test class also inherits the same package as the class under test.
-
For each test case we devise for the program/class, we write a test method. A JUnit test method returns void and is annotated with @Test (an annotation that comes from JUnit 5’s org.junit.jupiter.api.Test). The name of the test method does not matter to JUnit, but it does matter to us. A best practice is to name the test after the case it tests.
-
The test method instantiates the class under test and invokes the method under test. The test method passes the previously defined input in the test case definition to the method/class. The test method then stores the result of the method call (e.g., in a variable).
-
The test method asserts that the actual output matches the expected output. The expected output was defined during the test case definition phase. To check the outcome with the expected value, we use assertions. An assertion checks whether a certain expectation is met; if not, it throws an AssertionError and thereby causes the test to fail. A couple of useful assertions are:
- Assertions.assertEquals(expected, actual): Compares whether the expected and actual values are equal. The test fails otherwise. Be sure to pass the expected value as the first argument, and the actual value (the value that comes from the program under test) as the second argument. Otherwise the fail message of the test will not make sense.
- Assertions.assertTrue(condition): Passes if the condition evaluates to true, fails otherwise.
- Assertions.assertFalse(condition): Passes if the condition evaluates to false, fails otherwise.
- More assertions and additional arguments can be found in JUnit’s documentation. To make easy use of the assertions and to import them all in one go, you can use import static org.junit.jupiter.api.Assertions.*;.
import static org.junit.jupiter.api.Assertions.*;
import org.junit.jupiter.api.Test;
public class RomanNumeralTest {
@Test
void convertSingleDigit() {
RomanNumeral roman = new RomanNumeral();
int result = roman.convert("C");
assertEquals(100, result);
}
@Test
void convertNumberWithDifferentDigits() {
RomanNumeral roman = new RomanNumeral();
int result = roman.convert("CCXVI");
assertEquals(216, result);
}
@Test
void convertNumberWithSubtractiveNotation() {
RomanNumeral roman = new RomanNumeral();
int result = roman.convert("XL");
assertEquals(40, result);
}
}
AAA Automated tests: Arrange, Act, Assert
- Arrange: Define the input values that will be passed onto the automated test
- Act: Pass the input values by means of one or more method calls
- Assert: Execute assert instructions
@Test
void convertSingleDigit() {
// Arrange: we define the input values
String romanToBeConverted = "C";
// Act: we invoke the method under test
int result = roman.convert(romanToBeConverted);
// Assert: we check whether the output matches the expected result
assertEquals(100, result);
}
@BeforeEach
- JUnit runs methods that are annotated with @BeforeEach before every test method to avoid code duplication.
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import static org.junit.jupiter.api.Assertions.*;
class RomanNumeralTest {
private RomanNumeral roman;
@BeforeEach
void setup() {
roman = new RomanNumeral();
}
@Test
void convertSingleDigit() {
int result = roman.convert("C");
assertEquals(100, result);
}
@Test
void convertNumberWithDifferentDigits() {
int result = roman.convert("CCXVI");
assertEquals(216, result);
}
@Test
void convertNumberWithSubtractiveNotation() {
int result = roman.convert("XL");
assertEquals(40, result);
}
}
@ParameterizedTest
- We write a generic test method whose values are generated in runtime by the parameters of such method.
- To feed those values we define a source with
@MethodSource("generatorMethodName") private static Stream<Arguments> generator()returns aStream.of(arguments)that will be inserted as paramaters in the parameterized test method.- The arugments must have the same number of elements as the paramaterized method
- The parameterized method will be run each time for each stream of arguments sent
- To feed those values we define a source with
import org.junit.jupiter.params.ParameterizedTest;
import org.junit.jupiter.params.provider.Arguments;
import org.junit.jupiter.params.provider.MethodSource;
import java.util.stream.Stream;
import static org.junit.jupiter.api.Assertions.*;
class NumFinderTest {
// This one line instantiation in practice is run each time before each test
private final NumFinder n = new NumFinder();
@ParameterizedTest
@MethodSource("generator")
void getMinMax(int[] nums, int expectedMin, int expectedMax) {
n.find(nums);
assertEquals(expectedMax, n.getLargest());
assertEquals(expectedMin, n.getSmallest());
}
private static Stream<Arguments> generator() {
Arguments tc1 = Arguments.of(new int[]{27, 26, 25}, 25, 27);
Arguments tc2 = Arguments.of(new int[]{5, 2, 15, 27}, 2, 27);
return Stream.of(tc1, tc2);
}
}
@CsvSource
- The CsvSource expects list of strings, where each string represents the input and output values for one test case.
@ParameterizedTest(name = "small={0}, big={1}, total={2}, result={3}")
@CsvSource({
// The total is higher than the amount of small and big bars.
"1,1,5,0", "1,1,6,1", "1,1,7,-1", "1,1,8,-1",
// No need for small bars.
"4,0,10,-1", "4,1,10,-1", "5,2,10,0", "5,3,10,0",
// Need for big and small bars.
"0,3,17,-1", "1,3,17,-1", "2,3,17,2", "3,3,17,2",
"0,3,12,-1", "1,3,12,-1", "2,3,12,2", "3,3,12,2",
// Only small bars.
"4,2,3,3", "3,2,3,3", "2,2,3,-1", "1,2,3,-1"
})
void boundaries(int small, int big, int total, int expectedResult) {
int result = new ChocolateBars().calculate(small, big, total);
Assertions.assertEquals(expectedResult, result);
}
Testing techniques
Advantages of test automation
As in comparision to manually checking System.out.println…
- Less prone to human mistakes
- Faster than developers
- Efficient refactoring (you can change the code without having to change the tests)
Specification based testing (from requirements)
- These use the requirements of the program (often written as text; think of user stories and/or UML use cases) as input for testing.
- these techniques are also referred to as black box testing as they dont need you to know details such as in which software the program was developed or which data structures are used in the implementation
Partioning the input space
- Based on the requirements -> create paritions that represent each possible case -> create unit test
Equivalence partitioning
- The idea that inputs being equivalent to each other yield the same outcome (i.e. testing for multiples of 4 can take 4q with any q)
- Chosing 1 of the equivalent elements is more than enough
Category-Partition method (from method inputs)
- Systematic way of deriving test cases, based on the characteristics of the input parameters.
- reduces the number of tests to a practical number
- Identify the parameters, or the input for the program. For example, the parameters your classes and methods receive.
- Derive characteristics of each parameter. For example, an int year should be a positive integer number between 0 and infinite.
- Some of these characteristics can be found directly in the specification of the program.
- Others might not be found from specifications. For example, an input cannot be null if the method does not handle that well.
- Add constraints in order to minimise the test suite.
- Generate combinations of the input values. (Like a cartesian product)
- Exceptional cases can be just tested once and thus no need to combine them into the cartesian product (the constraints should be applied after the cartesian product).
Boundary testing
- Test that regard edge cases
- This boundaries regard the boundaries of test partitions
- we can find such boundaries by finding a pair of consecutive input values [p1,p2], where p1 belongs to partition A, and p2 belongs to partition B.
- However, in longer conditions, full of boundaries, the number of combinations might be too high, making it unfeasible for the developer to test them all.
On and Off points
- On-point: The on-point is the value that is exactly on the boundary. This is the value we see in the condition itself.
- Note that, depending on the condition, an on-point can be either an in- or an out-point.
- some authors argue that testing boundaries is enough. If the number of test cases is indeed too high, and it is just too expensive to do them all, prioritization is important, and we suggest testers to indeed focus on the boundaries.
- Off-point: The off-point is the value that is closest to the boundary and that flips the condition. If the on-point makes the condition true, the off point makes it false and vice versa. Note that when dealing with equalities or inequalities (e.g. x=6x = 6x=6 or x≠6x \neq 6x≠6), there are two off-points; one in each direction.
- In-points: In-points are all the values that make the condition true.
- Out-points: Out-points are all the values that make the condition false.
The problem is that this boundary is just less explicit from the requirements. Boundaries also happen when we are going from “one partition” to another. There is a “single condition” that we can use as clear source. In these cases, what we should do is to devise test cases for a sequence of inputs that move from one partition to another.
CORRECT way for boundary testing
- Conformance
- Test what happens when your input is not in conformance with what is expected. i.e. string instead of int, not an email, etc.
- Ordering
- Test different input order (i.e. sometimes the method only worked for sorted arrays)
- Range
- Test what happens when we provide inputs that are outside of the expected range. (i.e. negative numbers for age)
- Refference (for OOP methods)
- What it references outside its scope
- What external dependencies it has
- Whether it depends on the object being in a certain state
- Any other conditions that must exist
- Existence
- Does the system behave correctly when something that is expected to exist, does not? i.e. null pointer errors
- Cardinality
- Test loops in different situations, such as when it actually performs zero iterations, one iterations, or many.
- Time
- What happens if the system receives inputs that are not ordered in regards to date and time?
- Timing of successive events
- Does the system handle timeouts well?
- Does the system handle concurrency well? (multiple computations are happening at the same time.)
- Time formats and time zones
Domain testing
- combination of equivalent class analysis (the idea that inputs being equivalent to each other yield the same outcome, so just test 1 value for the partition, which was identified from the requirements and from the method inputs) and -> boundary testing (just test the on and off points)
- We read the requirement
- We identify the input and output variables in play, together with their types, and their ranges.
- We identify the dependencies (or independence) among input variables, and how input variables influence the output variable.
- We perform equivalent class analysis (valid and invalid classes).
- We explore the boundaries of these classes.
- We think of a strategy to derive test cases, focusing on minimizing the costs while maximizing fault detection capability.
- We generate a set of test cases that should be executed against the system under test.
Example
Basic structre:
Variables:
- a, explain
- b, explain
Dependencies:
I see some dependency between variables A and B, explain …
Equivalence partitioning and boundary analysis:
- variable A:
- partition 1
- partition 2
- variable B:
- partition 3
- partition 4
- (a, b)
- partition 5
- partition 6
- Boundaries
- boundary 1: explanation
- boundary 2: explanation
Structural testing
- Structural testing helped me in finding new test cases, A, B, and C…
- Domain tests and structural tests together achieve 100% branch+condition coverage.
Strategy:
- Combine everything from domain and structural testing…
- Total number of tests = 3
Test cases:
- T1 = …
- T2 = …
- T3 = …
Problem:
/**
* <p>Converts all the delimiter separated words in a String into camelCase,
* that is each word is made up of a titlecase character and then a series of
* lowercase characters.</p>
*
* <p>The delimiters represent a set of characters understood to separate words.
* The first non-delimiter character after a delimiter will be capitalized. The first String
* character may or may not be capitalized and it's determined by the user input for capitalizeFirstLetter
* variable.</p>
*
* <p>A <code>null</code> input String returns <code>null</code>.
* Capitalization uses the Unicode title case, normally equivalent to
* upper case and cannot perform locale-sensitive mappings.</p>
*
* @param str the String to be converted to camelCase, may be null
* @param capitalizeFirstLetter boolean that determines if the first character of first word should be title case.
* @param delimiters set of characters to determine capitalization, null and/or empty array means whitespace
* @return camelCase of String, <code>null</code> if null String input
*/
public String toCamelCase(String str, final boolean capitalizeFirstLetter, final char... delimiters) {
// ...
}
- The final char… delimiters allows you to pass any amount of delimiters by adding more char arguments. For example toCamelCase(“hello:world”, true, ‘:’, ‘;’) would have two delimiters. You can see this delimiters parameter as an array.
Answer:
- Variables:
- str - the original string
- capitalizeFirstLetter - boolean
- delimiters - array of chars
- output - CamelCased string
- Dependencies:
- There are no constraint dependencies among the input variables.
- Equivalence and Boundary Analysis:
- Variable str
- null
- empty
- non-empty single word
- non-empty multiple words
- Variable capitalizeFirstLetter
- true
- false
- Variable delimiters
- null
- no delimiter
- single delimiter
- multiple delimiters
- Variable delimiters, str:
- delimiter exists in the string
- delimiter does not exist in the string
- string consists of only delimiters
- Boundaries:
- No delimiter → single delimiter → multiple delimiters
- Single word → Multiple words
- Variable str
- Strategy
- Single tests for null and empty.
- Combine non-empty single word with all partitions in capitalize first letter
- Combine non-empty multiple words with (delimiters, str). Choose either true or false for capitalize first letter; we will not combine with it as the number of tests would grow very large
- Note that we choose words that are not already in the correct format.
- Test cases
- T1 null = (null, true, ‘.’) -> null
- T2 empty = (“”, true, ‘.’) -> “”
- T3 non-empty single word, capitalize first letter = (“aVOcado”, true, ‘.’) -> “Avocado”
- T4 non-empty single word, not capitalize first letter = (“aVOcado”, false, ‘.’) -> “avocado”
- T5 non-empty single word, capitalize first letter, no delimiter = (“aVOcado”, true) -> “Avocado”
- T6 non-empty single word, capitalize first letter, single existing delimiter = (“aVOcado”, true, ‘c’) -> “AvoAdo”
- T7 non-empty single word, capitalize first letter, single non-existing delimiter (skip as already tested with T4)
- T8 non-empty single word, capitalize first letter, multiple delimiters = (“aVOcado”, true, ‘c’, ‘d’) -> “AvoAO”
- T9 non-empty multiple words, capitalize first letter, no delimiter = (“aVOcado bAnana”, true) -> “AvocadoBanana”
- T10 non-empty multiple words, capitalize first letter, single existing delimiter = (“aVOcado-bAnana”, true, ‘-‘) -> “AvocadoBanana”
- T11 non-empty multiple words, capitalize first letter, single non-existing delimiter = (“aVOcado bAnana”, true, ‘x’) -> “AvocadoBanana”
- T12 non-empty multiple words, capitalize first letter, multiple delimiters, existing delimiter = (“aVOcado bAnana”, true, ‘ ‘, ‘n’) -> “AvocadoBaAA”
- T13 non-empty multiple words, capitalize first letter, multiple delimiters, non-existing delimiter = (“aVOcado bAnana”, true, ‘x’, ‘y’) -> “AvocadoBanana”
- T14 delimiters equal to null = (“apple”, true, null) -> “Apple”
- T15 only delimiters in the word = (“apple”, true, ‘a’, ‘p’, ‘l’, ‘e’) -> “apple”
package delft;
import static org.assertj.core.api.Assertions.*;
import java.util.stream.*;
import org.junit.jupiter.params.*;
import org.junit.jupiter.params.provider.*;
class Solution {
private final DelftCaseUtilities delftCaseUtilities = new DelftCaseUtilities();
@MethodSource("generator")
@ParameterizedTest(name = "{0}")
void domainTest(String name, String str, boolean firstLetter, char[] delimiters, String result) {
assertThat(delftCaseUtilities.toCamelCase(str, firstLetter, delimiters)).isEqualTo(result);
}
private static Stream<Arguments> generator() {
return Stream.of(Arguments.of("null", null, true, new char[]{'.'}, null),
Arguments.of("empty", "", true, new char[]{'.'}, ""),
Arguments.of("non-empty single word, capitalize first letter", "aVOcado", true, new char[]{'.'},
"Avocado"),
Arguments.of("non-empty single word, not capitalize first letter", "aVOcado", false, new char[]{'.'},
"avocado"),
Arguments.of("non-empty single word, capitalize first letter, no delimiters", "aVOcado", true,
new char[]{}, "Avocado"),
Arguments.of("non-empty single word, capitalize first letter, single delimiter", "aVOcado", true,
new char[]{'.'}, "Avocado"),
Arguments.of("non-empty single word, capitalize first letter, multiple delimiters", "aVOcado", true,
new char[]{'c', 'd'}, "AvoAO"),
Arguments.of("non-empty multiple words, capitalize first letter, no delimiters", "aVOcado bAnana", true,
new char[]{}, "AvocadoBanana"),
Arguments.of("non-empty multiple words, capitalize first letter, single existing delimiter",
"aVOcado-bAnana", true, new char[]{'-'}, "AvocadoBanana"),
Arguments.of("non-empty multiple words, capitalize first letter, single non-existing delimiter",
"aVOcado bAnana", true, new char[]{'x'}, "AvocadoBanana"),
Arguments.of("non-empty multiple words, capitalize first letter, multiple existing delimiters",
"aVOcado bAnana", true, new char[]{' ', 'n'}, "AvocadoBaAA"),
Arguments.of("non-empty multiple words, capitalize first letter, multiple non-existing delimiters",
"aVOcado bAnana", true, new char[]{'x', 'y'}, "AvocadoBanana"),
Arguments.of("delimiters is null", "apple", true, null, "Apple"),
Arguments.of("only delimiters in word", "apple", true, new char[]{'a', 'p', 'l', 'e'}, "apple"));
}
}
Structural testing
- Uses the source code to derive tests
- Helps us determine when to stop testing

Line coverage
- test line by line
- useful to do after doing requirements testing to fill in the coverage gaps
- Goal is that the line is exercised at least once by at least 1 test. It doesnt mean that all possible scenarios have been tested. Such is the case when all conditions are true, we can achieve 100% coverage, but we haven’t tested scenarios in which (some) conditions are false.
- Goal is to achieve 100% coverage
Block (Statement) coverage
- Normalizes the number of statement lines into blocks, as some developers might use more lines than others for the same block.
- Jacoco tests byte code level
- Uses a control flow graph (CFG)
- A basic block is composed of “the maximum number of statements that are executed together no matter what happens”. That is, until a condition is hit (a decision block), which is a romboid with only 2 edges (true and false).
CFG example
public String sameEnds(String string) {
int length = string.length();
int half = length / 2;
String left = "";
String right = "";
int size = 0;
for (int i = 0; i < half; i++) {
left = left + string.charAt(i);
right = string.charAt(length - 1 - i) + right;
if (left.equals(right)) {
size = left.length();
}
}
return string.substring(0, size);
}
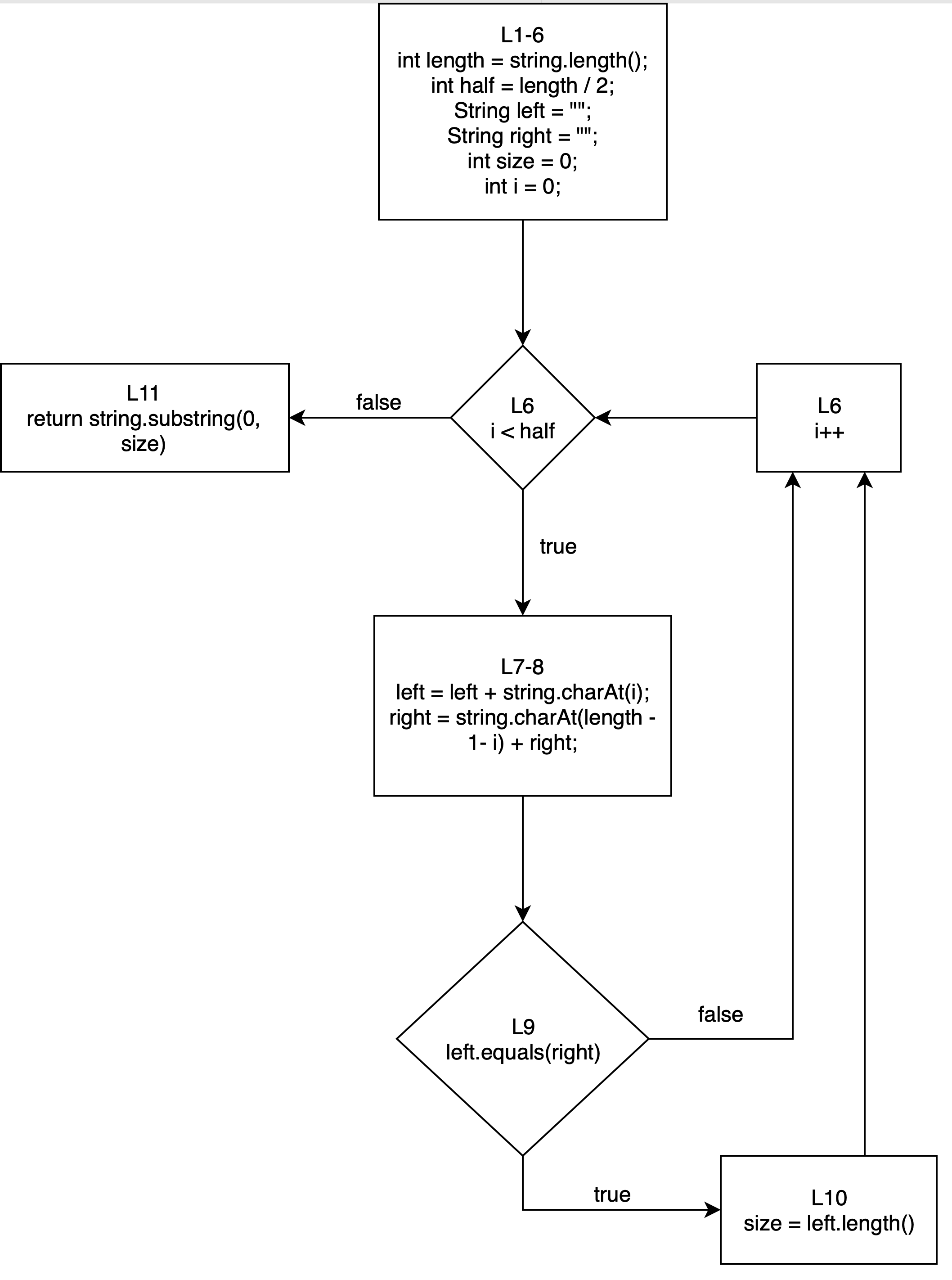
- we split the for loop into three blocks: the variable initialisation, the decision block, and the increment.
Branch (decision) coverage
- Make tests for each possible branch emerging from a condition
- Branch coverage gives two branches for each decision, no matter how complicated or complex the decision is
- Arrows with either true or false (i.e., both the arrows going out of a decision block) are branches, and therefore must be exercised.
- When a decision gets complicated, i.e., it contains more than one condition like a > 10 && b < 20 && c < 10, branch coverage might not be enough to test all the possible outcomes of all these decisions.
Condition coverage (Full branch coverage vs basic coverage)
- To do so we split the conditions into multiple decision blocks. This means each of the conditions will be tested separately, and not only the “big decision block”.
- Looking only at the conditions themselves while ignoring the overall outcome of the decision block is called basic condition coverage.
- Whenever we mention condition coverage or full condition coverage, we mean condition+branch coverage.
- A minimal test suite that achieves 100% branch coverage has the same number of test cases as a minimal test suite that achieves 100% full condition coverage.
- Be careful with lazy operators (&&, || …) as failing the first one will not exercise the next one(s) and thus might have impact on the condition coverage
Basic coverage:
- The basic condition coverage IS NOT 2^conditions (this is the path coverage), it’s just 2 x conditions (true or false)
Full coverage:
- Is the path coverage
Path coverage
- Whereas branch coverage only cares about executing a (sub-)condition as true and false, path coverage evaluates the (sub-)conditions in all the possible forms (i.e. a condition might have 4 variables so we need 2^4 tests to evaulate all scenarios)
- Path coverage does not consider the conditions individually. Rather, it considers the (full) combination of the conditions in a decision.
- It’s exponentially hard to achieve full path coverage, it is advised to just focus on the important ones.
- Another common criterion is the Multiple Condition Coverage, or MCC. To satisfy the MCC criterion, a condition needs to be exercised in all of its possible combinations. Path coverage is like this except for unbounded or long loops which may itereate an infinte number of times.
Boundary Adequacy
- Given that exhaustive testing is impossible, testers often rely on the loop boundary adequacy criterion to decide when to stop testing a loop:
- A test case exercises the loop zero times.
- A test case exercises the loop once.
- A test case exercises the loop multiple times.
- Rely on specification based techniques to determine the exact number of times to test.
Modified Condition/Decision Coverage (MC/DC)
- Instead of aiming at testing all the possible combinations, we follow a process in order to identify the “important” combinations.
- For N conditions you only need N+1 tests
- The idea of MC/DC is to exercise each condition in a way that it can, independently of the other conditions, affect the outcome of the entire decision. In short, this means that every possible condition of each parameter must have influenced the outcome at least once.
Design by contracts
Self testing
- Software systems that can test themselves
- Self-checks dont offer any user visible functionality they’re just an additional health check to report whether the system is working as expected
- Self-checks can be conducted during testing as well as live
- Self-checks are therefore included in the program itself (as opposed to the Junit tests)
Assertions
assert <condition> : "<message>";
public class MyStack(){
public Element pop() {
assert count() > 0;
// method body
}
}
- If the boolean expression
assert count() > 0is true, the program wont do nothing. - If the boolean expression is false, then it rasies an
AssertionError - However, assertion checking can be disabled at runtime.
- To enable the asserts, we have to run Java with a special argument in one of these two ways: java -enableassertions or java -ea. When using Maven or IntelliJ, the assertions are enabled automatically when running tests.
- When enabled, if an assert fails then it crashes the app, unless catched. Catching can only bring the system to a consistent state from which the app can be restarted.
- The idea of assertions is not to do logic checks (like those with illelArgumentException) but to act as sanity checks that the code has been written properly and does what it is supposed to do.
- You should never make a test that expects an assertion to fail. There must be no bug free scenario in which an assertion fails. That behaviour is undefined.
- They can also be used to expose interacting problems between modules (such as a third party library)
- Self-checks are more prevalent in DevOps
Test Oracles
- Informs us whether a piece of code has passed or failed
- Value comparision
- Version comparision
- Property checks
Assertions as Oracles
- Enable runtime assertion checking during testing
- Post-conditions check method outcomes
- Pre-conditions check correct method usage
- Invariants check object health
- Run time assertions increase fault sensitivity
- Increase likelihood program fails if there is a fault
- Desirable during testing
Pre- and post-conditions
- {P} A {Q} (also known as a Hoare Triple)
- given a state P, executing A yields Q
- Q = post-condition
- P = pre=condition
- preconditions are a design choice. Any adjustments we make in the preconditions can be moved to the body of the methodk
- A = method
assert PRECONDITION1;
assert PRECONDITION2;
//...
if (A) {
// ...
if (B) {
// ...
assert POSTCONDITION1;
return ...;
} else {
// ...
assert POSTCONDITION2;
return ...;
}
}
// ...
assert POSTCONDITION3;
return ...;
The method above has three conditions and three different return statements. This also gives us three post-conditions. In the example, if A and B are true, post-condition 1 should hold. If A is true but B is false, post-condition 2 should hold. Finally, if A is false, post-condition 3 should hold.
The placing of these post-conditions now becomes quite important, so the whole method is becoming rather complex with the post-conditions. Refactoring the method so that it has just a single return statement with a general post-condition is advisable. Otherwise, the post-condition essentially becomes a disjunction of propositions. Each return statement forms a possible post-condition (proposition) and the method guarantees that one of these post-conditions is met.
- The weaker the pre-conditions, the more situations a method is able to handle, and the less thinking the client needs to do. However, with weak pre-conditions, the method will always have to do the checking.
- The post-conditions are only guaranteed if the pre-conditions held; if not, the outcome can be anything. With weak pre-conditions the method might have to handle different situations, leading to multiple post-conditions.
Invariant
- Condition that holds throughout the lifetime of a system, an object or a data structure.
- (It is always true)
- A simple way of using invariants is by creating a “checker” method.
- Like the pre- & post- conditions, it throws
AssertionErrorwhen the boolean condition is false. - An invariant is often both a precondition and postcondition at the same time.
- Like the pre- & post- conditions, it throws
- Can also be implemented at the class level with
protected boolean invariant()method, which has to be asserted at the end of the class constructor method and at the start and end of each public method.- A class invariant ensures that its conditions will be true throughout the entire lifetime of the object.
- They can be used to test class hirearchies.
- A private method invoked by a public method can leave the object with the class invariant being false. However, the public method that invoked the private method should then fix this and end with the class invariant again being true.
- Static methods do not have invariants. Class invariants are related to the entire object, while static methods do not belong to any object (they are “stateless”), so the idea of (class) invariants does not apply to static methods.
Design by contracts
Interfaces as contracts
- A client and server are bound by a contract (where the pre conditions and post conditions are the respective binding clauses)
- The server promises to do its job (defined by the postconditions)
- As long as the client uses the server correctly (defined by the preconditions)
- These interfaces are used by the client and implemented by the server

Subcontracting
- In the UML diagram above, we see that the implementation can have different pre-, post-conditions, and invariants than its base interface.
- The implementation is a child of interface, therefore if we call a method of the implementation, it should be callable as often or more than the interface version. We want to ensure that the precondition of the interface is always met.
- P’ is weaker (or equal) than P
- The post condition of the interface must be always met, therefore the implementation precondition gets at least that done, or more.
- Q’ is stronger (or equal) than Q
- The invariant of the interface must always be true, therefore it must also be always true for the implementation.
- I’ is stronger (or equal) than I
Testing for Liskov Substitution Principle (LSP) Compliance
- Liskov substitution principle says that parent class tests hold for the children and hence these need not to be tested again, but inherit the test cases:
- Design test suite T at top interface level
- Reuse for all interface implementations
- Specific implementation may require additional tests, but should at least meet T

- We want to use the Factory Method design pattern in our tests for the List. We start by the interface level test class. Here, we define the abstract method that gives us a List.
public abstract class ListTest {
protected final List list = createList();
protected abstract List createList();
// Common List tests using list
}
- For this example, we create a class to test the ArrayList. We have to override the createList method and we can define any tests specific for the ArrayList.
public class ArrayListTest extends ListTest {
@Override
protected List createList() {
return new ArrayList();
}
// Tests specific for the ArrayList
}
- Now, the ArrayListTest inherits all the ListTest’s tests, so these will be executed when we execute the ArrayListTest test suite. Because the createList() method returns an ArrayList, the common test classes will use an ArrayList.
Example
package delft;
import java.util.HashMap;
import java.util.Map;
/** A square playing board. */
abstract class Board {
/** The size of the board. */
protected int size;
/**
* Creates a Board with a certain size.
*
* @param size
* the size of the board
* @throws IllegalArgumentException
* if the size is negative
*/
protected Board(int size) {
if (size < 0) {
throw new IllegalArgumentException("The size of the board cannot be negative.");
}
this.size = size;
}
/**
* Returns the Unit at a position of the board. If no such a Unit has been set
* before, it will return UNKNOWN.
*
* @param x
* x coordinate
* @param y
* y coordinate
* @return the unit at (x,y)
*/
public abstract Unit getUnit(int x, int y);
/**
* Sets the unit of a certain position on the board.
*
* @param x
* x coordinate
* @param y
* y coordinate
* @param unit
* the new unit for the position (x,y)
*/
public abstract void setUnit(int x, int y, Unit unit);
/**
* Checks whether the coordinates are in range and throws an exception if they
* aren't.
*
* @param x
* x coordinate
* @param y
* y coordinate
* @throws IllegalArgumentException
* when the coordinates are out of the range of the board
*/
protected void checkCoordinatesRange(int x, int y) {
if (x < 0 || x >= size || y < 0 || y >= size) {
throw new IllegalArgumentException(String.format("The position (%d, %d) does not exist.", x, y));
}
}
}
class MapBoard extends Board {
private final Map<Integer, Map<Integer, Unit>> board;
public MapBoard(int size) {
super(size);
board = new HashMap<>();
}
@Override
public Unit getUnit(int x, int y) {
checkCoordinatesRange(x, y);
if (board.containsKey(x) && board.get(x).containsKey(y)) {
return board.get(x).get(y);
}
return Unit.UNKNOWN;
}
@Override
public void setUnit(int x, int y, Unit unit) {
checkCoordinatesRange(x, y);
if (!board.containsKey(x)) {
board.put(x, new HashMap<>());
}
board.get(x).put(y, unit);
}
}
class ArrayBoard extends Board {
private final Unit[][] board;
public ArrayBoard(int size) {
super(size);
board = new Unit[size][size];
for (int i = 0; i < size; i++) {
for (int j = 0; j < size; j++) {
board[i][j] = Unit.UNKNOWN;
}
}
}
@Override
public Unit getUnit(int x, int y) {
checkCoordinatesRange(x, y);
return board[x][y];
}
@Override
public void setUnit(int x, int y, Unit unit) {
checkCoordinatesRange(x, y);
board[x][y] = unit;
}
}
enum Unit {
FRIEND, ENEMY, UNKNOWN
}
package delft;
import static org.assertj.core.api.Assertions.*;
import static org.junit.jupiter.api.Assertions.*;
import java.util.*;
import java.util.stream.*;
import org.junit.jupiter.api.*;
import org.junit.jupiter.params.*;
import org.junit.jupiter.params.provider.*;
abstract class BoardTest {
protected final Board board = createBoard(7);
abstract Board createBoard(int size);
@Test
void illegalSizeTest() {
assertThatThrownBy(() -> createBoard(-3)).isInstanceOf(IllegalArgumentException.class);
}
@Test
void createEmptyBoardTest() {
assertThat(createBoard(0)).isNotNull();
}
@MethodSource("illegalCoordinateBoundaryGenerator")
@ParameterizedTest(name = "illegal get coordinate ({0},{1}) test")
void getIllegalCoordinateTest(int x, int y) {
assertThatThrownBy(() -> board.getUnit(x, y)).isInstanceOf(IllegalArgumentException.class);
}
@MethodSource("illegalCoordinateBoundaryGenerator")
@ParameterizedTest(name = "illegal set coordinate ({0},{1}) test")
void setIllegalCoordinateTest(int x, int y) {
assertThatThrownBy(() -> board.setUnit(x, y, Unit.FRIEND)).isInstanceOf(IllegalArgumentException.class);
}
private static Stream<Arguments> illegalCoordinateBoundaryGenerator() {
return Stream.of(Arguments.of(-1, 2), Arguments.of(3, -1), Arguments.of(7, 2), Arguments.of(4, 7));
}
@MethodSource("validCoordinateBoundaryGenerator")
@ParameterizedTest(name = "valid get coordinate ({0}, {1}) test")
void boundaryGetTest(int x, int y) {
assertThat(board.getUnit(x, y)).isEqualTo(Unit.UNKNOWN);
}
private static Stream<Arguments> validCoordinateBoundaryGenerator() {
return Stream.of(Arguments.of(0, 3), Arguments.of(3, 0), Arguments.of(6, 2), Arguments.of(4, 6));
}
@Test
void getUnknownTest() {
assertThat(board.getUnit(6, 2)).isEqualTo(Unit.UNKNOWN);
}
@Test
void getPreviouslySetTest() {
board.setUnit(3, 2, Unit.ENEMY);
assertThat(board.getUnit(3, 2)).isEqualTo(Unit.ENEMY);
}
@Test
void getOtherElementOfPreviouslySetRowTest() {
board.setUnit(3, 2, Unit.ENEMY);
assertThat(board.getUnit(3, 4)).isEqualTo(Unit.UNKNOWN);
}
@Test
void setPreviouslySetTest() {
board.setUnit(0, 1, Unit.ENEMY);
board.setUnit(0, 1, Unit.FRIEND);
assertThat(board.getUnit(0, 1)).isEqualTo(Unit.FRIEND);
}
}
class MapBoardTest extends BoardTest {
@Override
Board createBoard(int size) {
return new MapBoard(size);
}
}
class ArrayBoardTest extends BoardTest {
@Override
Board createBoard(int size) {
return new ArrayBoard(size);
}
}
Property-Based testing
- Generates random inputs for the tests based on QuickCheck tool
public class PropertyTest {
@Property
void concatenationLength(@ForAll String s1, @ForAll String s2) {
String s3 = s1 + s2;
Assertions.assertEquals(s1.length() + s2.length(), s3.length());
}
}
- QuickCheck is a property specification language/library
- Data input generator for most default data types
- Mechanism to write your custom object generators
- Mechanism to constrain data generated (junit assume)
- Shrinking process to reduce inputs for failing tests to smallest input
- The java implementation we use is jqwik
Automated Self-Testing
- Random input generation
- Exercise system in variety of ways
- Clever generators for specific data types
- Whole test suite perspective
- Maximize coverage achieved by inputs
- Capture in fitness function
- Evolutionary search for fittest test suite
- Properties, contracts, assertions
- The oracle distinguishing success from failure
Examples
package delft;
class TaxIncome {
public static final double CANNOT_CALC_TAX = -1;
public double calculate(double income) {
if (0 <= income && income < 22100) {
return 0.15 * income;
} else if (22100 <= income && income < 53500) {
return 3315 + 0.28 * (income - 22100);
} else if (53500 <= income && income < 115000) {
return 12107 + 0.31 * (income - 53500);
} else if (115000 <= income && income < 250000) {
return 31172 + 0.36 * (income - 115000);
} else if (250000 <= income) {
return 79772 + 0.396 * (income - 250000);
}
return CANNOT_CALC_TAX;
}
}
package delft;
import static org.assertj.core.api.Assertions.*;
import static org.junit.jupiter.api.Assertions.*;
import java.util.*;
import java.util.stream.*;
import net.jqwik.api.*;
import net.jqwik.api.arbitraries.*;
import net.jqwik.api.constraints.*;
import org.junit.jupiter.api.*;
import org.junit.jupiter.params.*;
import org.junit.jupiter.params.provider.*;
class TaxIncomeTest {
private final TaxIncome taxIncome = new TaxIncome();
@Property
void tax22100max(@ForAll @DoubleRange(min = 0, max = 22100, maxIncluded = false) double income) {
assertEquals(taxIncome.calculate(income), 0.15 * income, Math.ulp(income));
}
@Property
void tax53500max(@ForAll @DoubleRange(min = 22100, max = 53500, maxIncluded = false) double income) {
assertEquals(taxIncome.calculate(income), 3315 + 0.28 * (income - 22100), Math.ulp(income));
}
@Property
void tax115000max(@ForAll @DoubleRange(min = 53500, max = 115000, maxIncluded = false) double income) {
assertEquals(taxIncome.calculate(income), 12107 + 0.31 * (income - 53500), Math.ulp(income));
}
@Property
void tax250000max(@ForAll @DoubleRange(min = 115000, max = 250000, maxIncluded = false) double income) {
assertEquals(taxIncome.calculate(income), 31172 + 0.36 * (income - 115000), Math.ulp(income));
}
@Property
void tax250000min(@ForAll @DoubleRange(min = 250000) double income) {
assertEquals(taxIncome.calculate(income), 79772 + 0.396 * (income - 250000), Math.ulp(income));
}
@Property
void invalid(@ForAll @Negative double income) {
assertEquals(taxIncome.calculate(income), -1, Math.ulp(income));
}
}
Testing Pyramid
- A large software system is composed of many units and responsibilities.

- As you climb the levels in the diagram, the tests become more realistic. At the same time, the tests also become more complex on the higher levels.
- The size of the pyramid slice represents the number of tests one would want to carry out at each test level.
Unit testing
- Testing a single feature while purposefully ignoring other units of the systems.
- A unit can span a single method, a whole class or multiple classes working together to achieve one single logical purpose that can be verified.
- Write unit tests when the component is about an algorithm or a single piece of business logic of the software system.
- Business logic often does not depend on external services and so it can easily be tested and fully exercised by means of unit tests.
- The way you design your classes has a high impact on how easy it is to write unit tests for your code.
Unit testing pros
- Fast execution
- Constant feedback allows for smooth evolutionary changes on the software
- Easy to control (easy to change inputs and expected outputs).
- Easy to write (easy setup and small tests)
Unit testing cons
- Lack of reality: Unit tests do not perfectly represent the real execution of a software system.
- Some types of bugs are not caught: Some types of bugs cannot be caught at unit test level. They only happen in the integration of the different components.
System testing
- Also known as black box testing (the system itself is regarded as a black box as we do not know everything that goes on inside of the system)
- Testing the system in its entirety (databases, front-end apps, etc.)
- Write system tests only after a risk-based approach where it is shown which parts of the systems are very bug prone, or where a specific part of the system must always be running, like the payment services of a webshop.
Black box testing pros
- Tests are realistic
- Tests capture the user perspective better than unit tests.
Black box testing cons
- Slower than unit tests
- Hard to write (especially setting up components for a testing scenario)
- They are “flaky” (fragile and bug prone): Due to their integration complexity often tests are not robust and do not manage to get the job done and deliver inconsistent results.
Integration testing
- Unit tests in isolation, blacbox tests the whole system, integration testing tests in between.
- The goal of integration testing is to test multiple components of a system together, focusing on the interactions between them instead of testing the system as a whole.
- Write integration tests whenever the component under test interacts with an external component (e.g., a database or a web service) integration tests are appropriate.
- making sure that the component that performs the integration is solely responsible for that integration and nothing else (i.e., no business rules together with integration code), will reduce the cost of the testing.
Integration testing pros
- Easier to write and less effort than system testing
Integration testing cons
- More complicated than a unit test
- The more integrated our tests are, the more difficult they are to write. In the example, setting up a database for the test requires effort. Tests that involve databases usually need to:
- make use of an isolated instance of the database just for testing purposes (as you probably do not want your tests to mess with production data),
- update the database schema (in fast companies, database schemas are changing all the time, and the test database needs to keep up),
- put the database into a state expected by the test by adding or removing rows,
- and clean everything afterwards (so that the next tests do not fail because of the data that was left behind by the previous test).
Manual testing
- Avoid them
Tsting pyramid at google
- Small test = unit test
- Medium test = integration test
- Large tests = system test
Test doubles
- We face challenges when unit testing classes that depend on other classes or on external infrastructure.
- It may creat an implicit dependency on a database, eventhough we dont really care about db behaviour. Therefore, we can unit test something assuming it’s dependencies work.
- To test A we mock the behaviour of component B. Within the test, we have full control over what this “fake component B” does so we can make it behave as B would in the context of this test and cut the dependency on the real object.
Test doubles pros
- We have more control: We can easily tell these objects what to do, without the need for complicated setups.
- Simulations are also faster: instead of waiting for a database API we can just return what we assume to be returned.
Types of doubles
- Dummy objects: Creating an object whose attributes are fake just for the porpuse of testing a method of that class
- Fake objects: They’re a poorman’s version of a more complex class, i.e. using an array list as a database object. They’re nonetheless working implmentations of the class they simulate.
- Stubs (Fixed Mockito): Stubs provide hard-coded answers to the calls that are performed during the test. Stubs do not actually have a working implementation, as fake objects do. Stubs do not know what to do if the test calls a method for which it was not programmed and/or set up.
- Spies: As the name suggests, spies “spy” a dependency. It wraps itself around the object and observes its behaviour. Strictly speaking it does not actually simulate the object, but rather just delegates all interactions to the underlying object while recording information about these interactions. Imagine you just need to know how many times a method X is called in a dependency: that is when a spy would come in handy. Example:
// this is a real list
List<String> list = new ArrayList<String>();
// this is a spy that will spy on the concrete list
// that is in the 'list' variable
List<String> spy = Mockito.spy(list);
// ...
spy.add(1); // this will call the concrete add() method
// ...
Mockito.verify(spy).add(1); // this will check whether add() was called
Furthermore, verify() is not limited to just mock spied objects, can also be used on mocked objects.
- Mocks: Mock objects act like stubs that are pre-configured ahead of time to know what kind of interactions should occur with them.
Mockito
- In general, we do not mock the class under test.
mock(<class>): creates a mock object/stub of a given class. The class can be retrieved from any class by.class. when(<mock>.<method>).thenReturn(<value>): defines the behaviour when the given method is called on the mock. In this casewill be returned. verify(<mock>).<method>: asserts that the mock object was exercised in the expected way for the given method.
import static java.util.Arrays.asList;
import static org.assertj.core.api.Assertions.assertThat;
import static org.mockito.Mockito.when;
public class InvoiceFilterTest {
private final IssuedInvoices issuedInvoices = Mockito.mock(IssuedInvoices.class);
private final InvoiceFilter filter = new InvoiceFilter(issuedInvoices);
@Test
void filterInvoices() {
final var mauricio = new Invoice("Mauricio", 20);
final var steve = new Invoice("Steve", 99);
final var arie = new Invoice("Arie", 300);
when(issuedInvoices.all()).thenReturn(asList(mauricio, arie, steve));
assertThat(filter.lowValueInvoices()).containsExactlyInAnyOrder(mauricio, steve);
}
}
- Mockito does not allow us to stub static methods (although some other more magical mock frameworks do). Static calls are indeed enemies of testability, as they do not allow for easy stubbing.
- It can be worked around by creating abstractions on top of dependencies that you do not own, which is a common technique among developers.
Mocking and stabbing
Stubbing means simply returning hard-coded values for a given method call. Mocking means not only defining what methods do, but also explicitly defining how the interactions with the mock should be.
Mockito actually enables us to define even more specific expectations. For example, see the expectations below:
verify(sap, times(2)).send(any(Invoice.class));
verify(sap, times(1)).send(mauricio);
verify(sap, times(1)).send(steve);
Developers often mock/stub the following types of dependencies:
- Dependencies that are too slow: If the dependency is too slow, for any reason, it might be a good idea to simulate that dependency.
- Dependencies that communicate with external infrastructure: If the dependency talks to (external) infrastructure, it might be too complex to be set up. Consider stubbing it.
- Hard to simulate cases: If we want to force the dependency to behave in a hard-to-simulate way, mocks/stubs can help.
Developers tend not to mock/stub:
- Entities. An entity is a simple class that mirrors a collection in a database, while instances of this class mirror the entries of that collection.
- Native libraries and utility methods. It is not common to mock/stub libraries that come with our programming language and utility methods. For example, why would one mock ArrayList or a call to String.format? As shown with the Calendar example above, any library or utility methods that harm testability can be abstracted away.
Trade-off:
- Whenever you mock, you reduce the reality of the test
- Mocks need to be updated as the objects they mock change
Mocking at google
- Using test doubles requires the system to be designed for testability. Dependency injection is the common technique to enable test doubles.
- Building test doubles that are faithful to the real implementation is challenging. Test doubles have to be as faithful as possible.
- Prefer realism over isolation. When possible, opt for the real implementation, instead of fakes, stubs, or mocks.
- Some trade-offs to consider when deciding whether to use a test double: the execution time of the real implementation, how much non-determinism we would get from using the real implementation.
- When using the real implementation is not possible or too costly, prefer fakes over mocks. An in-memory database, for example, might be better (or more real) than a mock.
- Excessive mocking can be dangerous, as tests become unclear (i.e., hard to comprehend), brittle (i.e., might break too often), and less effective (i.e., reduced fault capability detection).
- When mocking, prefer state testing rather than interaction testing. In other words, make sure you are asserting a change of state and/or the consequence of the action under test, rather than the precise interaction that the action has with the mocked object. After all, interaction testing tends to be too coupled with the implementation of the system under test.
- Use interaction testing when state testing is not possible, or when a bad interaction might have an impact in the system (e.g., calling the same method twice would make the system twice as slow).
- Avoid overspecified interaction tests. Focus on the relevant arguments and functions.
- Good interaction testing requires strict guidelines when designing the system under test. Google engineers tend not to do it.
Design for testability
- Testability is the term used to describe how easy it is to write automated tests for the system, class, or method to be tested.
Dependency injection
- Dependency injection is a design choice we can use to make our code more testable.
- Instead of the class instantiating the dependency itself, the class asks for the dependency (via constructor or a setter, for example).
- Example:
applyDiscount(){//check the Calendar static field date and apply discount}vsapplyDiscount(date){//apply discount based on passed parameters}, the second option makes the creation of automated tests easier and, therefore, increases the testability of the code.
- The use of dependency injection improves our code in many ways:
- It enables us to mock/stub the dependencies in the test code, increasing the productivity of the developer during the testing phase.
- It makes all the dependencies more explicit; after all, they all need to be injected (via constructor, for example).
- It affords better separation of concerns: classes now do not need to worry about how to build their dependencies, as they are injected to them.
- With Java, you generally need dependency injection to be able to mock dependencies, whereas JavaScript allows you to mock any imported dependency without changing the production code.
Domain vs infrastructure
- The domain is where the core of the system lies, i.e. where all the business rules, logic, entities, services, etc, reside.
- Infrastructure relates to all code that handles some infrastructure. For example, pieces of code that handle database queries, or webservice calls, or file reads and writes.
- When domain code and infrastructure code are mixed up together, the system becomes harder to test.
- Try to keep these 2 things separate from each other when making methods.
Implementation-level tips on designing for testability
- Cohesion and testability: cohesive classes are classes that do only one thing. Cohesive classes tend to be easier to test as a non-cohesive class requires exponential test cases.
- Coupling and testability: Coupling refers to the number of classes that a class depends on. A highly coupled class requires several other classes to do its work. Coupling decreases testability.
- Complex conditions and testability: Reducing the complexity of such conditions, for example by breaking it into multiple smaller conditions, will not reduce the overall complexity of the problem, but will “spread” it.
- Private methods and testability: In principle, testers should test private methods only through their public methods. Otherwise you should refactor it: extract this method, maybe to a brand new class. There, the former private method, now a public method, can be tested normally by the developer. The original class, where the private method used to be, should now depend on this new class.
- Static methods and testability: static methods adversely affect testability, as they can not be stubbed easily. Therefore, a good rule of thumb is to avoid the creation of static methods whenever possible. Exceptions to this rule are utility methods. As we saw before, utility methods are often not mocked.
- If your system has to depend on a specific static method, e.g., because it comes with the framework your software depends on, adding an abstraction on top of it might be a good decision to facilitate testability.
Web testing
Simplified architecture of a web application:

Javascript front-end
- Try to separate javascript from HTML
- Apply some kind of modular design, creating small, independent components that are easily tested
- Use a JavaScript library or framework (like Vue.js, React or Angular) in order to achieve such a structure
- Do a significant amount of refactoring to make the code testable
Client-server model
- The fact that the server side can be written in any programming language you like, means that you can stick to your familiar testing ecosystem there
- It poses challenges, like possibly having different programming languages and corresponding ecosystems on the client and server side
- Just testing the front and back end separately will probably not cut it
- Reflect how a user uses the application by performing end-to-end tests
- You have to have a web server running while executing such a test
- Server needs to be in the right state (especially if it uses a database), and the versions of front and back end need to be compatible
Everyone can access your application
- The users will have very different backgrounds. This makes usability testing and accessibility testing testing a priority
- The number of users of your application may become very high at any given point in time, so load testing is a wise thing to do
- Some of those users may have malicious intent. Therefore security testing is of utmost importance
The front end runs in a browser
- Different users use different versions of different browsers. Cross-browser testing helps to ensure that your application will work in the browsers you support
- Test for responsive web design to make sure the application will look good in browsers with different sizes, running on different devices
- HTML should be designed for testability, so that you can select elements, and so that you can test different parts of the user interface (UI) independently
- UI component testing can be considered a special case of unit testing: here your “unit” is one part of the Document Object Model (DOM), which you feed with certain inputs, possibly triggering some events (like “click”), after which you check whether the new DOM state is equal to what you expected
- Snapshot testing can help you to make sure your UI does not change unexpectedly
- To perform end-to-end tests automatically, you will have to somehow control the browser and make it simulate user interaction. Two well-known tools for this are Selenium WebDriver and Cypress.
Selenium WebDriver example
import org.junit.jupiter.api.Test;
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.firefox.FirefoxDriver;
import static org.assertj.core.api.Assertions.assertThat;
public class SeleniumWebDriverTest {
@Test
void spanishTitle() {
System.setProperty("webdriver.gecko.driver", "C:\\Users\\sergio\\OneDrive - Delft University of Technology\\CSE\\Y1\\Q4\\CSE1110 Software Quality and Testing\\geckodriver-v0.29.1-win64\\geckodriver.exe");
WebDriver driver = new FirefoxDriver();
driver.get("https://www.wikipedia.org");
WebElement link;
link = driver.findElement(By.id("js-link-box-es"));
link.click();
String title;
title = driver.getTitle();
assertThat(title).isEqualTo("Wikipedia, la enciclopedia libre");
}
}
Many web applications are asynchronous
- Most of the requests to the server are done in an asynchronous manner: while the browser is waiting for results from the server, the user can continue to use the application
- When writing unit tests, and end-to-end tests, you have to account for this by “awaiting” the results from the (mocked) server call before you can check whether the output of your unit matches what you expected
- This can leaad to flaky tests
- You either have to write custom code to make your tests more robust, or use a tool like Cypress, which has retry-and-timeout logic built-in
Javascript Unit testing
- Reasons why it is difficult or impossible to write unit tests for this piece of code:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8" />
<title>Date incrementer - version 1</title>
</head>
<body>
<p>Date will appear here.</p>
<button onclick="incrementDate(this)">+1</button>
<script>
function incrementDate(sender) {
var p = sender.parentNode.children[0];
var date = new Date(p.innerText);
date.setDate(date.getDate() + 1);
p.innerText = date.toISOString().slice(0, 10);
}
window.onload = function () {
var p = document.getElementsByTagName("p")[0];
p.innerText = new Date().toISOString().slice(0, 10);
}
</script>
</body>
</html>
- the JavaScript code is inline with the rest of the page (You cannot run the code without also running the rest of the page, so you cannot test the functions separately, as a unit). Just refactor it into seprate files.
- incrementDate() function is a mix of date logic and user interface (UI) code. These parts cannot be tested separately. We have also become dependent on the implementation of the date conversion functions. We should solve these problems by splitting up the incrementDate() function into different functions and storing the currently shown date in a variable.
- Another problem is that the initial date value is hard-coded: the code always uses the current date (by calling new Date()), so you cannot test what happens with cases like “February 29th, 2020”.
- The <p> element was difficult to locate using the standard JavaScript query selectors, and we resorted to abusing the DOM structure to find it. We thereby unnecessarily imposed restrictions on the DOM structure (the <p> element must now be on the same level as the button, and it must be the first element)
- For your UI tests, you should make sure that you can reliably select the elements you use.
- We can achieve this by adding an id to the element and then selecting it by using getElementById().
- In general, it is better to find elements in the same way that users find them (for example, by using labels in a form).
The aforementioned issues are solved by refactoring the code and splitting it up into three files. The first one (dateUtils.js) contains the utility functions for working with dates, which can now nicely be tested as separate units:
// Advances the given date by one day.
function incrementDate(date) {
date.setDate(date.getDate() + 1);
}
// Returns a string representation of the given date
// in the format yyyy-MM-dd.
function dateToString(date) {
return date.toISOString().slice(0, 10);
}
The second one (dateIncrementer.js) contains the code for keeping track of the currently shown date and the UI interaction:
function DateIncrementer(initialDate, dateElement) {
this.date = new Date(initialDate.getTime());
this.dateElement = dateElement;
}
DateIncrementer.prototype.increment = function () {
incrementDate(this.date);
this.updateView();
};
DateIncrementer.prototype.updateView = function () {
this.dateElement.innerText = dateToString(this.date);
};
The third one is the refactored HTML file (dateIncrementer2.html) that uses our newly created JavaScript files:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8" />
<title>Date incrementer - version 2</title>
</head>
<body>
<p id="pDate">Date will appear here.</p>
<button id="btnIncrement">+1</button>
<script src="dateUtils.js"></script>
<script src="dateIncrementer.js"></script>
<script>
window.onload = function () {
var incrementer = new DateIncrementer(
new Date(), document.getElementById("pDate"));
var btn = document.getElementById("btnIncrement");
btn.onclick = function () { incrementer.increment(); };
incrementer.updateView();
}
</script>
</body>
</html>
The date handling logic can now be tested separately, as well as the UI code. The initial date can now be supplied as an argument. The <p> element can now be found by its ID. We should now be ready to write some tests!
Javascript Unit test without framework
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8" />
<title>Date utils - Test</title>
</head>
<body>
<p>View the console output for test results.</p>
<script src="dateUtils.js"></script>
<script>
function assertEqual(expected, actual) {
if (expected != actual) {
console.log("Expected " + expected + " but was " + actual);
}
}
/*
Be aware that in JavaScript Date objects, months are zero-based,
meaning that month 0 is January, month 1 is February, etc.
So "new Date(2020, 1, 29)" represents February 29th, 2020.
*/
// Test 1: incrementDate should add 1 day a given date object
var date1 = new Date(2020, 1, 29); // February 29th, 2020
incrementDate(date1);
// This succeeds:
assertEqual(new Date(2020, 2, 1).getTime(), date1.getTime());
// Test 2: dateToString should return the date in the form "yyyy-MM-dd"
var date2 = new Date(2020, 4, 1); // May 1st, 2020
// This fails because of time zone issues
// (the actual value is "2020-04-30"):
assertEqual("2020-05-01", dateToString(date2));
</script>
</body>
</html>
Javascript UI test without framework
- It has to be done manually
- The state of the UI is not reset after the UI tests (so it’s a problem if you want to test more tests afterwards)
JavaScript unit testing (with React and Jest)
- Create a new React application using the Create React App tool
- This creates a project structure with the necessary dependencies and includes the unit testing framework Jest.
import { addOneDay, dateToString } from './dateUtils';
describe('addOneDay', () => {
test('handles February 29th', () => {
const oldDate = new Date(2020, 1, 29); // February 29th, 2020
const newDate = addOneDay(oldDate);
expect(newDate).toEqual(new Date(2020, 2, 1));
});
});
describe('dateToString', () => {
test('returns the date in the form "yyyy-MM-dd"', () => {
var date = new Date(2020, 4, 1); // May 1st, 2020
expect(dateToString(date)).toEqual("2020-05-01");
});
});
- We can now take advantage of the module system. We do not have to load the functions into global scope any more, but just import the functions we need.
- We use the Jest syntax, where describe is optionally used to group several tests together, and test is used to write a test case, with a string describing the expected behaviour and a function executing the actual test. The body of the test function uses the “fluent” syntax expect(…).toEqual(…)
Tests for the UI with Jest
- Here you see a similar Jest unit test structure, but we also use react-testing-library to render the UI component to a virtual DOM. In react-testing-library, you are encouraged to test components like a user would test them. This is why we use functions like getByText to look up elements. This also means that we did not have to include any ids or other ways of identifying the <p> and the < button > in the component.
import React from 'react';
import { render, fireEvent } from '@testing-library/react';
import DateIncrementer from './DateIncrementer';
test('renders initial date', () => {
const { getByText } = render(<DateIncrementer initialDate={new Date(2020, 0, 1)} />);
const dateElement = getByText("2020-01-01");
expect(dateElement).toBeInTheDocument();
});
test('updates correctly when clicking the "+1" button', () => {
const date = new Date(2020, 0, 1);
const { getByText } = render(<DateIncrementer initialDate={date} />);
const button = getByText("+1");
fireEvent.click(button);
const dateElement = getByText("2020-01-02");
expect(dateElement).toBeInTheDocument();
});
Jest mocks
jest.mock('./dateUtils');
import React from 'react';
import { render, fireEvent } from '@testing-library/react';
import { dateToString, addOneDay } from './dateUtils';
import DateIncrementer from './DateIncrementer';
test('renders initial date', () => {
dateToString.mockReturnValue("mockDateString");
const date = new Date(2020, 0, 1);
const { getByText } = render(<DateIncrementer initialDate={date} />);
const dateElement = getByText("mockDateString");
expect(dateToString).toHaveBeenCalledWith(date);
expect(dateElement).toBeInTheDocument();
});
test('updates correctly when clicking the "+1" button', () => {
const mockDate = new Date(2021, 6, 7);
addOneDay.mockReturnValueOnce(mockDate);
const date = new Date(2020, 0, 1);
const { getByText } = render(<DateIncrementer initialDate={date} />);
const button = getByText("+1");
fireEvent.click(button);
expect(addOneDay).toHaveBeenCalledWith(date);
expect(dateToString).toHaveBeenCalledWith(mockDate);
});
- Here, jest.mock(‘./dateUtils’) replaces every function that is exported from the dateUtils module by a mocked version. You can then provide alternative implementations with functions like mockReturnValue, and check whether the functions have been called with functions like expect(…).toHaveBeenCalledWith(…).
- The version with mocks is less ‘real’ than the one without. The one without mocks is arguably preferable. However, you could use the same mechanism for things like HTTP requests to a back end, and in that case mocking would certainly be helpful.
Snapshot testing
- Snapshot testing is useful if you want detect unexpected changes to the component output
- If all you want to do is make sure that your UI does not change unexpectedly, snapshot tests are a good fit.
- The first time you run a snapshot test, it takes a snapshot of the component as it is rendered in that initial run. That first time, the test will always pass. Then in all subsequent runs, the rendered output is compared to the snapshot. If the output is different, the test fails and you are presented with the differences between the two versions.
- The test runner allows you to inspect the differences and decide whether the changes are what you intended. You can then either change the component so that its output corresponds to the snapshot, or you press a button to update the snapshot and mark the newly rendered output as the correct one.
In Jest, such a test can look like this:
test('renders correctly via snapshot', () => {
const { container } = render(<DateIncrementer initialDate={new Date(2020, 0, 1)} />);
expect(container).toMatchSnapshot();
});
On the first run, this creates a file called DateIncrementer.test.js.snap with the following contents:
// Jest Snapshot v1, https://goo.gl/fbAQLP
exports[`renders correctly via snapshot 1`] = `
<div>
<div>
<p>
2020-01-01
</p>
<button>
+1
</button>
</div>
</div>
`;
On subsequent runs, the output of the test is compared to the corresponding snapshot.
The created snapshot file should be committed to your version control system (like Git), so that your tests can also run on your Continuous Integration (CI) system.
End-to-end testing
- The goal of end-to-end testing is to test the flow through the application as a user might follow it, while integrating the various components of the web application (such as the front end, back end and database)
- You should make this as realistic as possible, so you use an actual browser and perform the tests on a production-like version of the application components
- A well-known tool for this is Selenium WebDriver. It basically acts as a “remote control” for your browser, so you can instruct it to “open this page, click this button, wait for that element to appear”, etc. You write these tests in one of the supported languages (such as Java) with your favourite unit testing framework.
- The WebDriver API is now a W3C standard, and several implementations of it (other than Selenium) exist, such as WebDriverIO and Cypress.
- it is common to create an abstraction layer on top of the web application. In the context of web applications, the abstractions are called Page Objects.
Page objects

- The tool for communicating through the browser (such as WebDriver), gives an API to access the HTML elements. Additionally, the tool supports clicking on elements, for example on a certain button.
- We create a page object with just the methods that we need in the tests. These methods correspond to the application, rather than the HTML elements. The page objects implement these methods by using the API provided by the tool.
- the tests use these methods instead of the ones about the HTML elements. Because we are using methods that correspond to the application itself, they will be more readable than tests without the page objects.
- Page objects give us an abstraction for single pages or even fragments of pages. This is already better than using the API for the HTML elements in the test
State objects
- We can make the page objects correspond to the states in the navigational state machine.
- A navigational state machine is a state machine that describes the flow through a web application. Each page will be represented as a state object. The events of the transitions between these states show how the user can go from one to another page.
- In these state objects we have the inspection and trigger methods. Additionally, we have methods that can help with state self-checking.
- These methods verify whether the state itself is working correctly, for example by checking if certain buttons can be clicked on the web page.
- We have:
- class as a state machine
- inspection methods: extract information about the current state i.e. stack.get()
- trigger methods: transitions into the next state i.e. stack.pop() or stack.push(e)
- test scenario: sequence of triggers and inspections (to make assertions about the states)
Behaviour-driven design
- the system is designed with scenarios in mind
- These scenarios are written in natural language and describe the system’s behaviour in a certain situation.
- a tool for scenarios is cucumber.io, were a fixed format for scenarios is established
- Title of the scenario
- Given …: Certain conditions that need to hold at the start of the scenario.
- When …: The action taken.
- Then …: The result at the end of the scenario.
A user story usually consists of multiple scenarios with respect to the user introduced.
With the general Given, When, Then structure we can describe a state transition as a scenario. In general the scenario for a state transition looks like this:
Given I have arrived in some state
When I trigger a particular event
Then the application conducts an action
And the application moves to some other state.
Each scenario will be able to cover only one transition. To get an overview of the system as a whole we will still have to draw the entire state machine.
Usability and accessibility testing
- Traditionally, usability focuses more on “user-friendliness”; making the application pleasant and easy to use
- accessibility is about “making content accessible to a wider range of people with disabilities, including blindness and low vision, deafness and hearing loss, learning disabilities, cognitive limitations, limited movement, speech disabilities, photosensitivity and combinations of these.”
- To know what to test for, it is useful to consult resources like the Web Content Accessibility Guidelines (WCAG).
- You can use tools like “axe” to test your web pages for accessibility problems. However, at this stage, such tests often still need to be done manually.
- Install assistive technologies like a screen reader that reads aloud the pages you load in your browser, and see whether you can still use the application without using your eyes.
- ask a user with a disability to use your application and help you with identifying issues in it.
Load and performance testing
- If users have to wait too long for your application to load, they may lose interest and turn to somewhere else
- you should make sure that your application still functions properly when used by lots of people.
- various tool exist for system load testing
Automated visual regression testing (screenshot testing)
- Screenshot tests work in a similar way to snapshot tests.
- the assertion is made on the end visual result that the user sees and it does not depend on the implementation details of the UI.
- A page of the web application is visited.
- A screenshot of the page is taken and compared with the previously taken screenshot of that page.
- If there is not a screenshot to compare to the test passes and saves the image as a baseline. If there are differences between the images the test fails and the difference can be manually inspected and verified to see if the results were intended or not.
- A popular tool in the web ecosystem to create and run automated visual regression tests is BackstopJS.
SQL testing
- A common case for integration testing are classes that talk to databases.
- Business applications are often composed of many Data Access Objects (DAOs) that perform complex SQL queries
What to test in a SQL query?
- As a tester, a possible criteria is to exercise the different predicates and check whether the SQL query returns the expected results when predicates are evaluated to different results.
- Specification-based testing: These SQL queries emerge out of a requirement. A tester can analyse the requirements and derive equivalent partitions that need to be tested.
- Boundary analysis: Such programs have boundaries. Given that we can also expect boundaries to be places with a high bug probability, exercise them is therefore also important.
- Structural testing: Structurally-speaking, SQL queries contain predicates, and a tester might use the SQL’s structure to derive test cases.
- the WHERE clause constitutes a single branch with n predicates and 2^n paths, of which, regardless of the logic, the branch is either true or false and for the condition coverage you can assume that the key word AND is a lazy operator.
Five guidelines for designing SQL tests:
- Adopting MC/DC for SQL conditions. Decisions happen at three places in a SQL query: join, where and having conditions. Testers can make use of a criteria such as MC/DC to fully exercise its predicates.
- Adapting MC/DC for tackling with nulls. Given that databases have a special way of handling/returning NULLs, any (coverage) criteria should be adapted to a three-valued logic (i.e., true, false, null). In other words, consider the possibility of values being null in your query.
- Category partitioning selected data. SQL can be considered a sort of declarative specification, of which we can define partitions to be tested.
- Rows that are retrieved: We include a test state to force the query to not select any row.
- Rows that are merged: The presence of unwanted duplicate rows in the output is a common failure in some queries. We include a test state in which identical rows are selected.
- Rows that are grouped: For each of the group-by columns, we design test states to obtain at least two different groups at the output, such that the value used for the grouping is the same, and all the other are different.
- Rows that are selected in a subquery: For each subquery, we include test states that return zero and more rows, with at least one null and two different values in the selected column
- Values that participate in aggregate functions: For each aggregate function (excluding count), we include at least one test state in which the function computes two equal values and another one that is different.
- Other expressions: We also design test states for expressions involving the like predicate, date management, string management, data type conversions or other functions using category partitioning and boundary checking.
- Checking the outputs. We should check not only the input domain, but also the output domain. SQL queries might return NULL in specific columns or empty sets, for example, which might make the rest of the program to break.
- Databases have constraints. Testers should make sure these constraints are indeed enforced by the database.
How to write automated test cases for SQL queries
(1) establish a connection with the database (2) make sure the database is in the right initial state (3) fire a SQL query (4) check the output
- We clean the entire database to make sure our tests will not be flaky
- After each class, we close the connection, to avoid connection leaks
- Use methods with persistance
- Use methods that retrieve
- Test what is retreived
Challenges and best practices
- Make use of test data builders. They will help you to quickly build the data structures you need.
- Make use of good assertions APIs. Asserting was easy in the example above as AssertJ makes our life easier.
- Minimize the required data. Make sure the input data is minimized. You do not want to have to load hundreds of thousands of elements to exercise your SQL query (maybe you will want to do this to exercise other features of your database, like speed, but that is not the case here).
- Build good test infrastructure. In our example, it was simple to open a connection, to reset the database state, and etc, but that might become more complicated (or lenghty) once your database schema gets complicated. Invest on a test infrastructure to facilitate your SQL testing.
- Take into consideration the schema evolution. In real life, database schemas evolve quite fast. Make sure your test suite is resilient towards these changes (i.e., if an evolution should not break the test suite, it does not; if an evolution should break the test suite, it does break the test suite).
- Consider an in-memory database. You should decide whether your tests will communicate with a “real” database (i.e., the same database of your production environment) or a simpler database (e.g., an in-memory database). As always, both sides have advantages and disadvantages. Using a the same database as in production makes your tests more realistic, but probably slower than if you use an in-memory database
Test Driven Development
- One disadvantage of first wirting production code, and then test, is that this creates a delay before we have tests, causing us to miss the “design feedback” that our tests can give us.
- Test-Driven Development (TDD) proposes the opposite: to write the tests before the production code.
TDD Cycle
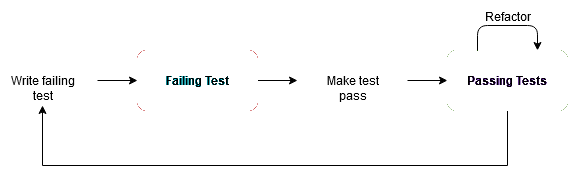
- With a given requirement, we start by thinking of test cases. Start with single simple test, which will fail, make it pass, etc. as in the diagram above.
- Keep adding tests and repeat the process
- The aim is to write the simplest production code that makes the test pass
- Refactor the code we have written. This is because, when focusing on making the test pass, we might have ignored the quality of our production code
- Repeat the process from the beginning
- Stop once we are satisfied with our implementation and the requirement is met
TDD Pros
- By creating the test first, we also look at the requirements first.
- This makes us write the code for the specific problem that it is supposed to solve (the code does what it is supposed to do).
- In turn, this prevents us from writing unnecessary code.
- We can control our pace of writing production code.
- Once we have a failing test, our goal is clear: to make the test pass. With the test that we create, we can control the pace we follow when writing the production code. If we are confident about how to solve the problem, we can make a big step by creating a complicated test. However, if we are not sure how to tackle the problem, we can break it into smaller parts and start by creating tests for these and then proceed with the other parts.
- Testable code from the beginning.
- Creating the tests first makes us think about the way to test the classes before implementing them
- It improves the testability, and more specifically also the controllability of our code
- Feedback on design. The properties of the tests we write can indicate certain types of problems in the code. This is why Test-Driven Development is sometimes called Test-Driven Design.
- Too many tests for just one class can indicate that the class has too many functionalities and that it should be split up into more classes.
- If we need too many mocks inside of the tests, the class might be too coupled
- If it is very complex to set everything up for the test, we may have to think about the pre-conditions that the class uses
- Quick feedback on the code that we are writing.
- Instead of writing a lot of code and then a lot of tests, i.e. getting a lot of feedback at once after a long period of time, we create a test and then write a small piece of code for that test. It becomes easier to identify new problems as they arise, because they relate to the small amount of code that was added last
- Baby steps
- TDD encourages developers to work in small (baby) steps: first define the smallest possible functionality, then write the simplest code that makes the test green, and carry out one refactoring at a time.
When to use TDD
- You should use TDD when you do not know how to design and/or architect a part of the system (or dealing with a complex problem).
- The use of baby steps might help you to start slowly, to learn more about the requirement, and to get up to speed once you are more familiar with the problem.
- TDD might help you to explore different design decisions.
- You should not use TDD when you are familiar with the problem, or the design decisions are clear in your mind. If there is “nothing to be learned or explored”, TDD might not really afford any significant benefit.
- Even if you are not doing TDD, you should write tests in a timely manner.
- Write them together with the production code, so that the growing automated test suite will give you more and more confidence about the code.
Test code quality and engineering
- As with production code, developers have to put extra effort into making high-quality test code bases, so that these can be maintained and developed in a sustainable way.
FIRST properties
- Fast: Tests are the safety net of a developer. Whenever developers perform any maintenance or evolution in the source code, they use the feedback of the test suite to understand whether the system is still working as expected. The faster the developer gets feedback from their test code, the better. Once you are facing a slow test, you may consider to:
- Make use of mocks/stubs to replace slower components
- Re-design the production code so that slower pieces of code can be tested separately from fast pieces of code
- Move slower tests to a different test suite, one that developers may run less often.
- Isolated: Tests should be as cohesive, as independent (that is, the success of a test shall not depend on having run a previous test), and as isolated as possible since tests should test just a single functionality or behaviour of the system.
- JUnit’s
@BeforeEachor@BeforeAllmethods can become handy.
- JUnit’s
- Repeatable: gives the same result, no matter how many times it is executed. (it’s not flaky)
- Common causes of flakyness are dependencies on external resources, not waiting long enough for an external resource to finish its task, and concurrency.
- Self-validating: It is not uncommon for developers to make mistakes and not write any assertions in a test, causing the test to always pass. The tests should validate/assert the result themselves.
- In cases where observing the outcome of behaviour is not easily achievable, we suggest the developer to refactor the class or method under test to increase its observability
- Timely: Developers should be test infected. They should write and run tests as often as possible. If you test at the end the systme might be too hard to test.
Test Desiderata from the author of Test-Driven Development
- Isolated: tests should return the same results regardless of the order in which they are run.
- Composable: if tests are isolated, then I can run 1 or 10 or 100 or 1,000,000 and get the same results.
- Fast: tests should run quickly.
- Inspiring: passing the tests should inspire confidence.
- Writable: tests should be cheap to write relative to the cost of the code being tested.
- Readable: tests should be comprehensible for their readers, and it should be clear why they were written.
- Behavioural: tests should be sensitive to changes in the behaviour of the code under test. If the behaviour changes, the test result should change.
- Structure-insensitive: tests should not change their result if the structure of the code changes.
- Automated: tests should run without human intervention.
- Specific: if a test fails, the cause of the failure should be obvious.
- Deterministic: if nothing changes, the test result should not change.
- Predictive: if the tests all pass, then the code under test should be suitable for production.
Testcode smells
- The term code smell is a well-known term that indicates possible symptoms that might indicate deeper problems in the source code of the system
- Code smells hinder the comprehensibility and the maintainability of software systems.
- While the term has long been applied to production code, given the rise of test code, our community has been developing catalogues of smells that are now specific to test code
- We discuss below several of the well-known test smells:
1. Code Duplication
- Tests are often similar in structure.
- We even made use of parameterised tests to reduce some of the duplication
- A less attentive developer might end up writing duplicated code (copying and pasting often happens in real life) instead of putting some effort into implementing a better solution.
- Duplicated code can reduce the productivity of software testers. After all, if there is a need for a change in a duplicated piece of code, a developer will have to apply the same change in all the places where the code was duplicated. (the effects are similar to the effects of code duplication in production code. The extraction of a duplicated piece of code to private methods or external classes is often a good solution for the problem.)
2. Assertion Roulette
- Some features or business rules are so complex that they require a complex set of assertions hard to understand. Therefore try to:
- Write customised assert instructions that abstract away part of the complexity of the assertion code itself.
- Write code comments that explain quickly and in natural language what those assertions are about. (This mainly applies when the assertions are not self-explanatory.)
- A common best practice that is often found in the test best practice literature is the “one assertion per method” strategy.
3. Resource Optimism
- Resource optimism happens when a test assumes that a necessary resource (e.g., a database) is readily available at the start of its execution.
- To avoid resource optimism, a test should not assume that the resource is already in the correct state. The test should be the one responsible for setting up the state itself. (Use
@BeforeEachor@BeforeAll) - Another incarnation of the resource optimism smell happens when the test assumes that the resource is available all the time, which might be actually down for reasons we do not control. To avoid this:
- Avoid using external resources, by using stubs and mocks.
- If the test cannot avoid using the external dependency, make it robust enough. Make your test suite skip that test when the resource is unavailable, and provide a message explaining why that was the case.
- Continuous integration tools like Jenkins, CircleCI, and Travis can help developers in making sure that tests are being run in the correct environment.
4. Test Run War
- Analogy for when two tests are “fighting” over the same resources. One can observe a test run war when tests start to fail as soon as more than one developer run their test suites. (i.e. by using the same database and causing temporary illegal states accessed by others)
- Isolation is needed to fix this test smell. In the example of a centralised database, one solution would be to make sure that each developer has their own instance of a database. That would avoid the fight over the same resource.
5. General Fixture
- A fixture is the set of input values that will be used to exercise the component under test. (“the arrange part”).
- When testing more complex components, developers may need to make use of several different fixtures: one for each partition they want to exercise. These fixtures can then become complex. And to make the situation worse, while tests are different from each other, their fixtures might have some intersection.
- A less attentive developer could decide to declare a “large” fixture that works for many different tests. Each test would then use a small part of this large fixture.
- This is hard to mantain and it should not be done. Making sure that the fixture of a test is as specific and cohesive as possible helps developers to comprehend the essence of a test (which is often highly relevant when the test starts to fail).
- Build patterns, with the focus of building test data, can help developers in avoiding such a smell. The Test Data Builder pattern is a good example.
6. Indirect tests and eager tests
- The smell emerges when a test class focuses its efforts on testing many classes at once.
- Tests, and more specifically, unit test classes and methods, should have a clear focus. They should test a single unit. If they have to depend on other classes, the use of mocks and stubs can help the developer in isolating that test and avoid indirect testing, or at least make sure that assertions focus on the real class under test (and that failures caused by dependencies (and not by the class under test) are clearly indicated in the outcome of the test method).
- Avoiding eager tests, or tests that exercise more than a unique behaviour of the component is also best practice
- Test methods that exercise multiple behaviours at once tend to be overly long and complex, making it harder for developers to comprehend them quickly.
7. Sensitive Equality
- Test code should be as resilient as possible to the implementation details of the component under test. Assertions should also not be oversensitive to internal changes.
- A good assertion asserts precisely what is wanted from the method/class under test, and shall not rely on other methods (i.e. toString, external libraries, etc.) as those might be overriden in the future without going under the radar and cause unexpected assert results.
8. Inappropriate assertions
- The wrong choice of an assertion instruction may give developers less information about the failure, making the debugging process more difficult. (i.e. using asserTrue( object a == object b) when assertEquals(a,b) would give more information).
- Libraries such as AssertJ, besides making the assertions more legible, also help us in providing better error messages:
- Virgin JUnit:
assertTrue(items.contains("Playstation")); assertTrue(items.contains("Big TV")); - Chad AssertJ:
assertThat(items).containsExactlyInAnyOrder("Playstation", "Big TV");
- Virgin JUnit:
9. Mystery Guest
- Integration tests often rely on external dependencies. These dependencies, or “guests”, can be things like databases, files on the disk, or webservices. While such dependencies are unavoidable in these types of tests, making them explicit in the test code may help developers in cases where these tests suddenly start to fail.
- A test that makes use of a guest, but hides it from the developer (making it a “mystery guest”) is simply harder to comprehend.
- Make sure your test gives proper error messages, differentiating between a fail in the expected behaviour and a fail due to a problem in the guest.
- Having assertions dedicated to ensuring that the guest is in the right state before running the tests is often the remedy that is applied to this smell.
Testcode readability
- We need readable and understandable test code
- All tests follow the same structure:
- Arrange
- Act
- Assert
- Your tests should make sure that a developer can identify these parts quickly and get the answers to the following questions:
- Where is the fixture?
- Where is the behaviour/method under test?
- Where are the assertions?
- we should make sure that the (meaning of the) important information present in a test is easy to understand (and separate it from the complex things). Test Data Builders help with that:
Test Data Builder
Instead of:
public class Invoice {
private final BigDecimal value;
private final String country;
private final CustomerType customerType;
public Invoice(BigDecimal value, String country, CustomerType customerType) {
this.value = value;
this.country = country;
this.customerType = customerType;
}
public BigDecimal calculate() {
double ratio = 0.1;
// some business rule here to calculate the ratio
// depending on the value, company/person, country ...
return value.multiply(new BigDecimal(ratio));
}
}
With thest:
@Test
void test1() {
var invoice = new Invoice(new BigDecimal("2500"), "NL", CustomerType.COMPANY);
var v = invoice.calculate();
assertEquals(250, v.doubleValue(), 0.0001);
}
We can implement, the InvoiceBuilder, which is simply a Java class. The trick that allows methods to be chained is to return the class itself in the methods (note that methods return this):
public class InvoiceBuilder {
private String country = "NL";
private CustomerType customerType = CustomerType.PERSON;
private BigDecimal value = new BigDecimal("500.0");
public InvoiceBuilder withCountry(String country) {
this.country = country;
return this;
}
public InvoiceBuilder asCompany() {
this.customerType = CustomerType.COMPANY;
return this;
}
public InvoiceBuilder withAValueOf(String value) {
this.value = new BigDecimal(value);
return this;
}
public Invoice build() {
return new Invoice(value, country, customerType);
}
}
With the much clearer test:
@Test
void taxesForCompanies() {
var invoice = new InvoiceBuilder()
.asCompany()
.withCountry("NL")
.withAValueOf("2500")
.build();
var calculatedValue = invoice.calculate();
assertThat(calculatedValue).isCloseTo(new BigDecimal("250"), within(new BigDecimal("0.001")));
}
- A common trick is to make the builder build a “common” version of the class, without requiring the call to all the setup methods.
- Introducing test data builders, making good use of variable names to explain the meaning of the information, having clear assertions, and adding comments in cases where code is not expressive enough will help developers in better comprehending test code.
Flaky tests
- they sometimes pass and sometimes fail, even though developers have not performed any changes in their software systems.
- presence of flaky tests can make developers lose confidence in their test suites.
- Such lack of confidence might lead them to deploy their systems even though the tests are failing (but the reason of the fails might not be necessarily flakiness but actuall wrong production code)
- A test can be flaky because it depends on external and/or shared resources. For example, when we need a database to run our tests
- The tests can be flaky due to improper time-outs that dont allow enough time for the dependency to load and make the expected changes.
- Tests can be flaky due to a possible hidden interaction between different test methods
- If the flaky test gets worse overtime
- Then Probably Resource Leakege
- Else Probably non-deterministic test
- If Happens when test run alone?
- Then Probably lonely test (only works when executed alone (i.e. depends on a specific db state))
- Else probably Interacting tests (only works after other tests set up the desired state)
Security Testing
Software vs security testing
- The goal of software testing is to check the correctness of the implemented functionality
- The goal of security testing is to find bugs (i.e. vulnerabilities) that can potentially allow an intruder to make the software misbehave.
- What makes a security vulnerability different from a typical software bug is the assumption that an intruder may exploit it to cause harm
- Similar to traditional software testing, thorough testing does not guarantee the absence of security vulnerabilities.
- security testing is not a one-off event, but has to be incorporated in the whole Software Development Life Cycle.
Java vulnerabilities
- Java is memory-safe: it handles memory management and garbage collection itself, unlike C that requires developers to handle these tasks themselves. This is a common reason to assume that Java apps do not suffer from, e.g. buffer overflows. However, several core Java components are built upon native C code for optimization purposes, making them potential targets.
- The top 3 vulnerability types are related to bypassing controls, executing code in unauthorized places, and causing denial of service. Hence, we see that although memory corruption is not a major threat for Java applications, the effects caused by classical buffer overflows in C applications can still be achieved in Java by other means.
- An infinite loop can be triggered by attackers to do a Denial of Service attack.
Code injection vulnerability
The code snippet below has a Code Injection vulnerability.
Socket socket = null;
BufferedReader readerBuffered = null;
InputStreamReader readerInputStream = null;
/*Read data using an outbound tcp connection */
socket = new Socket("host.example.org", 39544);
/* Read input from socket */
readerInputStream = new InputStreamReader(socket.getInputStream(), "UTF-8");
readerBuffered = new BufferedReader(readerInputStream);
/* Read data using an outbound tcp connection */
String data = readerBuffered.readLine();
Class<?> tempClass = Class.forName(data);
Object tempClassObject = tempClass.newInstance();
IO.writeLine(tempClassObject.toString());
// Use tempClass in some way
The Class.forName(data) is the root cause of the vulnerability as it will dynamically add the code from host.example.org:39544 which if infected will also infect the code.
- Update attack in android applications is an example of this.
- To limit its effect, developers can disallow ‘untrusted’ plugins, and can limit the privileges that a certain plugin has, e.g. by disallowing plugins to access sensitive folders.
Type confusion vulnerability
- This vulnerability was present in the implementation of the tryfinally() method in the Reflection API of the Hibernate ORM library.
- Due to insufficient type checks in this method, an attacker could cast objects into arbitrary types with varying privileges.
- an attacker can use this type confusion vulnerability to escalate their privileges by bypassing the Java Security Manager (JSM).
- The attacker’s goal is to access System.security object and set it to null, which will disable the JSM. However, the security field is private and cannot be accessed by just any object.
- So, they will exploit the type confusion vulnerability to cast Obj into an object with higher privileges that has access to the System.security field.
- Once the JSM is bypassed, the attacker can execute whatever code they want to.
Arbitrary Code Execution
- A common misconception is that Java, unlike C, is not vulnerable to Buffer overflows.
- In fact, any component implemented in native C code is just as vulnerable to exploits as the original C code would be.
- An earlier version of a GIF library in the Sun JVM contained a memory corruption vulnerability: A valid GIF component with the block’s width set to 0 caused a buffer overflow when the parser copied data to the under-allocated memory chunk. This overflow caused multiple pointers to be corrupted, and resulted in Arbitrary Code Execution (see CVE-2007-0243 for more details).
- A similar effect was caused by an XML deserialization bug in the XStream library: while deserializing XML into a Java Object, a malicious XML input caused the memory pointer to start executing code from arbitrary memory locations (which could potentially be controlled by an attacker).
-
When an ACE is triggered remotely, it is called a Remote Code Execution (RCE) vulnerability. The underlying principle is the same: it is also caused by Improper handling of ‘special code elements’.
- (Buffer overflows, Deserialising bugs, Type confusion) underlying defects that enable arbitrary code execution
The Secure Software Development Life Cycle (Secure-SDLC)
- Security testing is a type of non-functional testing. But if it fails:
- There is a high impact on the functionality of the application, e.g. a denial of service attack that makes the entire application unreachable
- High chance of monetary/reputation loss
- At the planning phase, risk assessment should be done and potential abuse cases should be designed that the application will be protected against.
- In the analysis phase, the threat landscape should be explored, and attacker modelling should be done.
- The design and implementation plans of the application should include insights from the attacker model and abuse cases.
- Implement
- Security testing should be a part of the testing and integration phases. Code reviews should also be done from the perspective of the attacker (using abuse cases)
- During the maintenance phase, in addition to bug fixes, developers should keep an eye on the CVE database (Common Vulnerabilities and Exposures) and update (if possible) the vulnerable components in the application.
- CWE (Common Weakness Enumeration): determines the type of vulnerability
- CVSS (Common Vulnerability Scoring System): score that determines the severity of the vulnerability
- Most companies solely do penetration testing which tests the entire application at the very end of the SDLC.
- The problem with penetration testing is that it tests the application as a whole, and does not stress-test each individual component.
- When security is not an integral part of the design phase, the vulnerabilities discovered in the penetration testing phase are patched in an ad-hoc manner that increase the risk of them falling apart after deployment
Facets of security testing
- the term security testing is very broad and it covers a number of overlapping concepts. We classify them as follows:
| White-box | Black-box | |
|---|---|---|
| Static Application Security Testing | Code checking, Pattern matching, ASTs, CFGs, DFDs | Reverse engineering |
| Dynamic Application Security Testing | Tainting, Dynamic validation, Symbolic execution | Penetration testing, Reverse engineering, Behavioural analysis, Fuzzing |
- In the context of automated security testing, static and dynamic analysis are called Static Application Security Testing (SAST) and Dynamic Application Security Testing (DAST), respectively.
Quality assessment criteria
- You have already learnt about code coverage in previous chapters. Here, we discuss four new metrics that are often used in the context of security testing.
- Designing an ideal testing tool requires striking a balance between two measures. (Looking for Vulnerability)
- Soundness: no vulnerability should be skipped. (0 FN)
- Completeness: no false alarm should be raised. (0 FP)
- True Positives (TP) are actual bugs, and True Negatives (TN) are actual benign code snippets. Similarly, False Positives (FP) are false bugs (or false alarms), and False Negatives (FN) are bugs that weren’t found (or missed bugs)
- If a vuln exists, then a sound system will always detect it. It will never miss out on a vulnerability. Hence, 0 FNs.
-
If no vuln exists, then a sound system may still raise alarms, and these will be the false alarms (FPs).
- Only when no vuln exists, will a complete system not raise any alarms. It will never raise any false alarm. Hence, 0 FPs.
- If a vuln exists, it is still possible that a complete system raises no alarm, hence missing a vulnerability. This is called a FN.
So, in short, a sound system guarantees 0 FNs but may raise FPs, while a complete system guarantees 0 FPs but may cause FNs.
- You want both minimal False Positives and minimal False Negatives but in practice the tools will often compromise either.
- Additionally, an ideal testing tool is
- interpretable: an analyst can trace the results to a solid cause
- scalable: the tool can be used for large applications without compromising heavily on performance.
Static Application Security Testing (SAST)
- SAST techniques aim to find security bugs without running the application. (system under test or SUT)
- They can find bugs that can be observed in the source code and for which signatures can be made, e.g. SQL Injection and basic Cross-Site Scripting (XSS and XSRF are tricky because input sanitization methods can be bypassed at run-time.)
- SpotBugs, FindSecBugs, and Coverity are static analysis tools specially meant to test security problems in applications.
- Risk-based testing is a business-level process where we model the worst-case scenarios (or abuse cases) using threat modelling.
- Risk-based testing can be done both statically (if the abuse-case targets problems found in source code) and dynamically (for run-time threats).
Code checking for security
- Pattern matching via RegEx: Pattern matching can find simplistic security issues, such as:
- Misconfigurations, like port 22 being open for every user,
- Potentially bad imports, like importing the whole System.IO namespace,
- Calls to dangerous functions, like strcpy and memcpy.
- Syntax anlysis via Abstract Syntax Trees (AST):
- This is an example of the famous Format string attack, which exploits a vulnerability in the printf() function family: in the absence of a format string parameter like %s, an attacker can supply their own format string parameter in the input, which will be evaluated as a pointer resulting in either arbitrary code execution or a denial of service.
Structural testing for security
- Control Flow Graphs can also be used for to help testers pin-ppoint strange control transfers:
- an unintended transition going from a low- to a high- privileged code block
- certain unreachable pieces of code that can result in application hanging and eventually, a denial of service.
- Data flow diagrams (DFG) are built on top of CFG and show how data traverses through a program. Since Data Flow Analysis (DFA) is also a static approach, a DFD tracks all possible values a variable might have during any execution of the program
- This can be used to detect sanitization problems, such as the deserialization vulnerability that caused an ACE (Arbitrary Code Execution), and some simplistic code injection vulnerabilities.
- In DFA, we prove that (a) No tainted data is used, and (b) No untainted data is expected. An alert is raised if either of the two conditions are violated.
The code snippet below shows a real case that DFA can detect. The variable data is tainted, as it is received from a user. Without any input cleaning, it is directly used in println() method that expects untainted data, thus raising an alert.
/* Uses bad source and bad sink */
public void bad(HttpServletRequest request, HttpServletResponse response)
throws Throwable {
String data;
/* Potential flaw: Read data from a queryString using getParameter */
data = request.getParameter("name");
if (data != null) {
/* Potential flaw: Display of data in web pages after using
* replaceAll() to remove script tags,
* will still allow XSS with string like <scr<script>ipt>. */
response.getWriter().println("<br>bad(): data = " +
data.replaceAll("(<script>)", ""));
}
}
- Another application of is Reaching Definitions a top-down approach that identifies all the possible values of a variable. For security purposes, it can detect
- Type Confusion vulnerability
- Use-after-free vulnerability (which uses a variable after its memory has been freed).
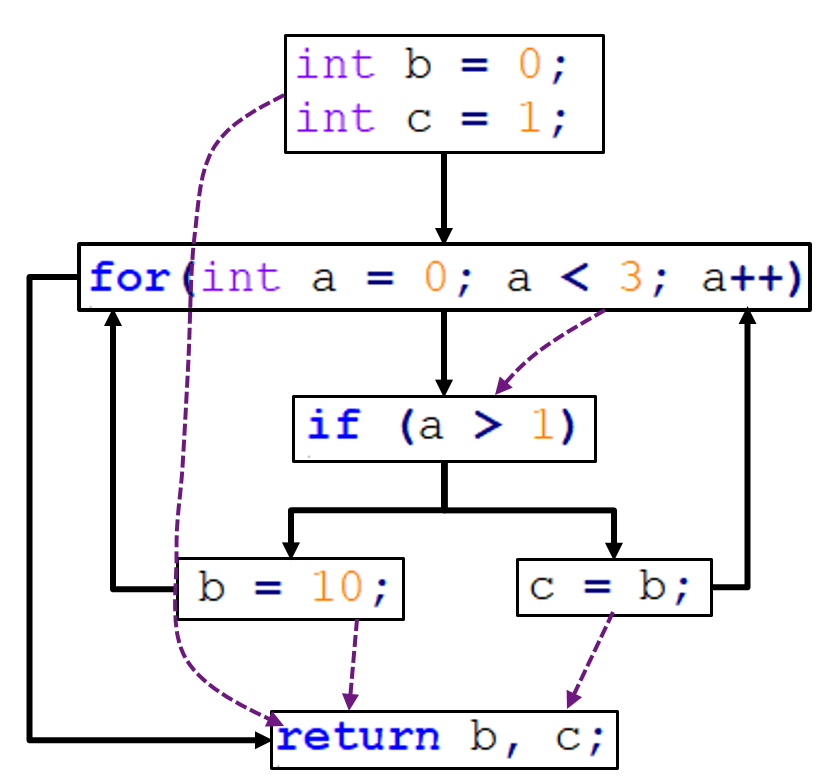
- The solid transitions show control transfers
- he dotted transitions show data transfers
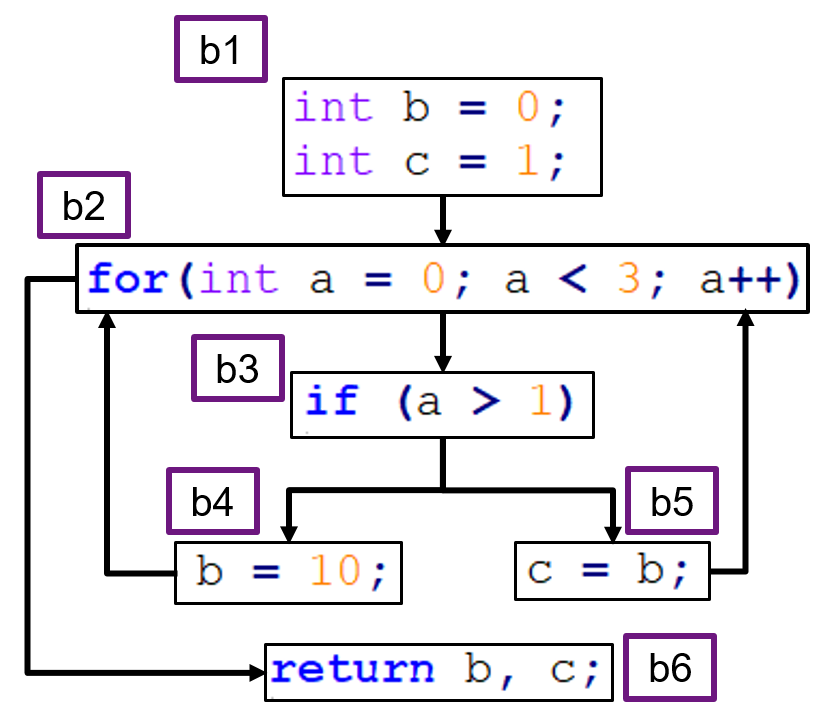
| code blocks | a | b | c |
|---|---|---|---|
| b1 | - | 0 | 1 |
| b2 | 0, a++ | - | - |
| b3 | - | - | - |
| b4 | - | 10 | - |
| b5 | - | - | b |
| b6 | - | - | - |
- we label each basic block, and draw a table that lists the variable values in each block.
- If a variable is not used in the block, or the value remains the same, nothing is listed.
- Remember, if the value of a variable is controlled by a user-controlled parameter, it cannot be resolved until run-time, so it is written as is
- whether a loop terminates is an undecidable problem (also called the halting problem), so finding the actual values that a looping variable takes on is not possible using static analysis.
Dynamic Application Security Testing (DAST)
- DAST techniques execute an application and observe its behaviour
- Such as crashes and DDOS
- DAST tools typically do not have access to the source code, they can only test for functional code paths
- hey need to be hooked-up with the SUT, sometimes even requiring to modify the system under test codebase, e.g. for instrumentation.
- they typically produce less false positives and more advanced results compared to SAST tools (more complete)
Taint analysis
- Taint analysis is the dynamic version of Data Flow Analysis
- we track the values of variables that we want to taint, by maintaining a so-called taint table.
- we analyse how the value propagates throughout the codebase and affects other statements and variables.
- To enable tainting, code instrumentation is done by adding hooks to variables that are of interest
- Pin is an instrumentation tool from Intel, which allows taint analysis of binaries.
Dynamic validation
- Dynamic validation does a functional testing of the SUT based on the system specifications.
- Model Checking is a similar idea in which specifications are cross-checked with a model that is learnt from the SUT.
- They analyse processes that may contain race conditions that an attacker may exploit to gain control over a system
- To check the existence of such scenarios, they codify it in a property that stops a program from passing the same filename to two system calls on the same path.
- Once codified in a model checker, they run it on various applications and report on deviations from this property.
- It is important to note that not all security properties can be codified into specifications.
Penetration testing
- the most common type of security testing for organizations (sometimes referred to as Ethical hacking)
- it is done from the perspective of an attacker
- Penetration testing checks the SUT in an end-to-end fashion, which means that it is done once the application is fully implemented, so it can only be done at the end of the SDLC
- MetaSploit is an example of a powerful penetration testing framework. Most pen testing tools contain a Vulnerability Scanner module that either runs existing exploits, or allow the tester to create an exploit
- They also contain Password Crackers that either brute-force passwords (i.e. try all possible combinations given some valid character set), or perform a dictionary attack (i.e. choose inputs from pre-existing password lists).
Behavioural analysis
- behavioural analysis aims to gain insights about the software by generating behavioural logs and analysing them.
- The logs can be compared with known-normal behaviour in order to debug the SUT.
- Example is a videogame where scores can only go up and you test a random AI and observe if the scores follows the expected behaviour
- Behavioural logs are a good data source for forensic analysis of the SUT.
Reverse Engineering
- the goal is to reveal the internal structure of an application.
- converts a black-box application into a white-box.
- strictly speaking, not a testing technique, but it is useful when (i) converting legacy software into a modern one, or (ii) understanding a competitor’s product.
- This model can then be used for, e.g. Dynamic validation, and/or to guide path exploration for better code coverage.
Fuzzing
- Fuzzing or fuzz testing is an automated software testing technique that involves providing invalid, unexpected, or random data as inputs to a computer program. The program is then monitored for exceptions such as crashes, failing built-in code assertions, or potential memory leaks.
SAST vs DAST
- Static analysis tools create a lot of FPs because they cannot see the run-time behaviour of the code. They also generate FNs if they don’t have access to some code, e.g. code that is added at run-time.
- Dynamic analysis reduces both FPs and FNs — if an action is suspicious, an alarm will be raised. However, even in this case, we cannot ensure perfect testing.
- Static analysis is generally more white-box than dynamic analysis, although there are interpretable dynamic testing methods, like symbolic execution.
- Static testing is more scalable in the sense that it is faster, while black-box dynamic testing is more generalizable.
- SAST is fast, but generates many false positives. DAST is operationally expensive, but generates insightful and high-quality results.
- ASTs make the code structure analysis easy. CFGs and DFDs are better at finding security vulnerabilities.
- Update attack cannot be detected by static analysis.
- XSS and XSRF are also tricky for static analysis as input sanitization methods can be bypassed at run-time.
- Static analysis is good at format string injection
Intelligent testing
Static testing
- Static testing analyses the code characteristics without executing the application
- It checks the style and structure of the code, and can be used to statically evaluate all possible code paths in the System Under Test (SUT)
- It can be considered as an automated code review
- Static analysis can quickly find low-hanging fruit bugs that can be found in the source code, e.g. using deprecated functions.
- Static analysis tools are scalable and generally require less time to set up.
- PMD, Checkstyle, Checkmarx are some common static analysis tools.
- A code checker typically contains a parser and an acceptable rule set:
- Pattern matching via Regular expressions
- Syntax analysis via Abstract Syntax Trees
- It generates Sound but Incomplete results
Pattern matching
- Pattern matching is a code checking approach that searches for pre-defined patterns in code, often via regular expressions or RegEx.
- While regular expressions are a fast and powerful pattern matching technique, their biggest limitation is that they do not take semantics (the context) into account.
Syntax analysis
- It works by deconstructing the input into a stream of characters, that are eventually turned into a Parse Tree.
- A Parse Tree is a concrete instantiation of the code, where each character is explicitly placed in the tree, whereas an Abstract Syntax Tree (AST) is an abstract version of the parse tree in which syntax-related characters, such as semi-colon and parentheses, are removed. An example of the AST of the code snippet above is given below.
boolean DEBUG = false;
if (DEBUG){
System.out.println("Debug line 1");
System.out.println("Debug line 2");
System.out.println("Debug line 3");
}
- A static analysis tool using syntax analysis takes as input (a) an AST, and (b) a rule-set, and raises an alarm in case a rule is violated
- Doing this with just regex would be ubercomplex
- Abstract Syntax Trees are used by compilers to find semantic errors
- ASTs can also be used for program verification, type-checking, and translating the program from one language to another.
Another example, for (a + b) * (c - d):
Mutation Testing
- Reminder that
adequacy criteriameasured how “thouroughly” our test suit exercises the program under analysis, with path coverage > branch coverage > block coverage. Which are the coverage criteria for white-box testing. - Mutation criteria is the extent to which the tests are ablke to detect faults.
- Research has shown that mutation score provides a better measure for the fault detection capability than the test coverage.
- “Mutation” comes from inserting artificial defects (mutants) in the production code to asses the quality of the test code.
- Effective test suites are those that while pass mutant-free, are more likely to fail when mutants are added to the production code.
- Mutation testing is like testing teh tests
- Mutant: Given a program PPP, a mutant called P′P’P′ is obtained by introducing a syntactic change to PPP. A mutant is killed if a test fails when executed with the mutant.
- Syntactic Change: A small change in the code. Such a small change should make the code still valid, i.e., the code can still compile and run.
- Change: A change, or alteration, to the code that mimics typical human mistakes.
Fault Detection Capability
- The fault detection capability. It indicates the test’s capability to reveal faults in the system under test.
- If you dont use assertions then you’re not gonna be able to reveal a failure (unless the system crashes or throws an exception)
- We can indicate the quality of our test suite in a better way than with just the coverage metrics we have so far.
- It literally regards the assertions made in the test cases and their meaningfulness
- In mutation testing we change small parts of the production code and check if the tests can find the introduced fault.
Example:
public class Division {
public static int[] getValues(int a, int b) {
if (b == 0) {
return null;
}
int quotient = a / b;
int remainder = a % b;
return new int[] {quotient, remainder};
}
}
If we use a test case with getValues(1,1), changing int quotient = a / b to int quotient = a * b would give the same test result. Therefore getValues(1,1) has a low mutation (fault detection capability).
Hypotheses for Mutation testing
- The amount of mutation in the soruce code is defined along the lines of:
- The Competent Programmer Hypothesis (CPH): We assume that the program is written by a competent programmer. Given a certain specification, the programmer creates a program that is either correct, or it differs from a correct program by a combination of simple errors.
- The Coupling Effect: Simple faults are coupled with more complex faults. Test cases that detect simple faults, will also detect complex faults.
- This indicates that the mutant size should be small.
Automation
- There are various tools that generate mutants for mutant testing automatically, but they all use the same methodology.
- A mutation operator is a grammatical rule that can be used to introduce a syntactic change. (i.e. change + to -)
- Real fault based operators: Operators that are very similar to defects seen in the past for the same kind of code.
- AOR - Arithmetic Operator Replacement: Replaces an arithmetic operator by another arithmetic operator. Arithmetic operators are +, -, *, /, %.
- ROR - Relational Operator Replacement: Replaces a relational operator by another relational operator. Relational operators are <=, >=, !=, ==, >, <.
- COR - Conditional Operator Replacement: Replaces a conditional operator by another conditional operator. Conditional operators are &&, ||, &, |, !, ^.
- AOR - Assignment Operator Replacement: Replaces an assignment operator by another assignment operator. Assignment operators include =, +=, -=, /=.
- SVR - Scalar Variable Replacement: Replaces each variable reference by another variable reference (of the same data type i.e. an int for an int) that has already been declared in the code. (swaping variables)
- Language-specific operators: Mutations that are made specifically for a certain programming language. For example, changes related to the inheritance feature we have in Java, or changes regarding pointer manipulations in C.
- Access Modifier Change
- Hiding Variable Deletion
- Hiding Variable Insertion
- Overriding Method Deletion
- Parent Constructor Deletion
- Declaration Type Change
- Real fault based operators: Operators that are very similar to defects seen in the past for the same kind of code.
Mutation Analysis and Testing
- we run the test suite against each of the mutants with an execution engine
- If any test fails when executed against a mutant, we say that the test suite kills the mutant.
- This is good, because it shows that our test suite has some fault detection capability.
- When performing mutation testing, we count the number of mutants our test suite killed and the number of mutants that are still alive
- the best scenario is to have all the mutants killed by the test suite. While this is indeed the best scenario, it is often unrealistic because some of the mutants may be impossible to kill.
- Mutants that cannot be killed are called equivalent mutants, it always behaves in the same way as the original program.
- Program equivalence roughly means that two programs are functionally equivalent when they produce the same output for every possible input.
- We do not want to take the equivalent mutants into account, as there is nothing wrong with the tests when they do not kill these mutants.
- \[\text{mutation score } = \frac{\text{killed mutants}}{\text{non-equivalent mutants}}\]
- detecting equivalent mutations is an undecidable problem. We can never be sure that a mutant behaves the same as the original program for every possible input.
- mutation score provides a better measure for the fault detection capability than the test coverage. But it is more time expensive:
- We have to generate the mutants, possibly remove the equivalent mutants, and execute the tests with each mutant. Shortcuts:
- A test case can never kill a mutant if it does not cover the statement that changed (also known as the reachability condition). Based on this observation, we only have to run the test cases that cover the changed statement. One test that kills the mutant is enough.
- Another way to reduce time is to reduce the number of mutant operators to mutate from, as having a mutant from 1 swap will probably create other mutants, fixing it will also fix the other possible choices.
- The process of determining the mutation score cannever be fully automated while being accurate, as an accurate score depends on weeding out equivalent mutations, which is an undecidable/NP-hard problem.
- If similar mutants are not discarded, the runtime of mutation testing would be very long, greatly reducing usability. Not discarding similar mutants also skews the mutation score.
- We have to generate the mutants, possibly remove the equivalent mutants, and execute the tests with each mutant. Shortcuts:
- One of the most mature mutation testing tools for Java is PIT
- Mutation analysis: assesing the quality of the test suite by computing the mutation score
- Mutation testing: improving the quality of the test suite by using mutants
Number of mutants
Take a look at the method min(int a, final int b, final int c) from org.apache.commons.lang3.math.NumberUtils:
/**
* <p>Gets the minimum of three {@code int} values.</p>
*
* @param a value 1
* @param b value 2
* @param c value 3
* @return the smallest of the values
*/
public static int min(int a, final int b, final int c) {
if (b < a) {
a = b;
}
if (c < a) {
a = c;
}
return a;
}
Which of the following mutation operators can be applied to the method in order to obtain a mutant?
- Arithmetic Operator Replacement (+, -, *, /, %)
- Relational Operator Replacement (<, >, <=, >=, !=, ==)
-
Conditional Operator Replacement (&, , &&, , !, ^) - Assignment Operator Replacement (=, +=, -=, /=)
- Scalar Variable Replacement
for lines 10 and 13 we can use Relational Operator Replacement with 6 potential operators minus the original for lines 11 and 14 we can use Assignment Operator Replacement with 6 potential values minus the original for lines 10, 11, 13, 14 and 16 contain a total of 9 variables that can be repalced with Scalar Variable Replacement with 3 potential values minus the original one.
We would have 2(6-1) for ROR We would have 2(4-1) for AOR We would have 9*(3-1) Scalar Variable Replacments Total: 10 + 6 + 18 = 34 mutants
We can also consider higher-order mutation. There, all the combinations of mutants can be applied. Again, on the given method we have 2 instances of relational operators, 2 instances of assignment operators, and 9 instances of scalar variables. The upper-bound estimate of the number of mutants becomes: 6^2 * 4^2 * 3^9 - 1 = 11337407 mutants.
Fuzz testing
- Fuzzers bombard the System Under Test (SUT) with randomly generated inputs in the hope to cause crashes
- A crash can either originate from failing assertions, memory leaks, or improper error handling.
- It has been successful in discovering unknown bugs in software.
- Random fuzzing is the most primitive type of fuzzing, where the SUT is considered as a completely black box
- it takes a long time to generate any meaningful test cases.
- Most software takes some form of structured input that is pre-specified, so we can exploit that knowledge to build more efficient fuzzers.
- Mutation-based Fuzzing creates permutations from example inputs to be given as testing inputs to the SUT. These mutations can be anything ranging from replacing characters to appending characters. It does not take the specifications of the input into account (thus often generating invalid inputs).
- Generation-based Fuzzing, also known as Protocol fuzzing, takes the file format and protocol specification of the SUT into account when generating test cases. Compared to mutative fuzzers, generative fuzzers are less generalisable and more difficult to set up, but provide higher-quality tests.
- Fuzzers can be used in a variety of ways to achieve high code coverage in a reasonable time:
- Multiple tools: Use multiple fuzzing tools. Each fuzzer performs mutations in a different way, so they can be run together to cover different parts of the search space in parallel.
- Telemetry as heuristics: used to halt fuzzing prematurely by selecting only those mutations that increase code coverage.
- Symbolic execution: limit the search-space covered by a fuzzer with the help of symbolic execution by specifying bounds on variable values that ensure the coverage of a desired path, using so-called symbolic variables.
- We assign symbolic values to these variables rather than explicitly enumerating each possible value.
- Note that it is not always possible to determine the potential values of a variable because of the halting problem — answering whether a loop terminates with certainty is an undecidable problem.
Search-based software testing
- randomly generating test cases might not work well (i.e. achieve high coverage) for complicated programs.
- Chances are that branches that need very specific input will never be generated
- Search-based software testing aims to optimize random test case generation by relying on genetic algorithms.
- The most popular tool for search-based automated test case generation is EvoSuite
Random test case generation
- Radoop can generate random test cases by:
- Instantiate the class under test.
- If the constructor has parameters, pass random values to it.
- Invoke the method under test.
- If the method has parameters, pass random values to it.
- If the method returns a value, store it.
- Check the output produced by the program and use it to write the assertion.
- Measure the achieved (branch) coverage.
- Repeat the procedure until the entire budget (e.g. a timeout) is consumed.
- Randoop can be used for two purposes:
- to find bugs in your program
- to create regression tests to warn you if you change your program’s behavior in the future
The oracle problem
- Given that tools such as Randoop and EvoSuite cannot really know what the correct output is, it uses the output that the program gives as assertions. In this sense, tests that are produced by these tools do not reveal the functional bugs one would manually find.
- However we can utilize the generation of random inputs to find unkown cases in which an exception is thrown or a crash appears and automatically label them as bugs.
- When Randoop calls a method that creates an object, Randoop verifies that the object is well-formed. Currently, Randoop checks for the following contracts:
- Contracts over Object.equals():
- Reflexivity: o.equals(o) == true
- Symmetry: o1.equals(o2) == o2.equals(o1)
- Transitivity: o1.equals(o2) && o2.equals(o3) ⇒ o1.equals(o3)
- Equals to null: o.equals(null) == false
- it does not throw an exception
- Contracts over Object.hashCode():
- Equals and hashcode are consistent: If o1.equals(o2)==true, then o1.hashCode() == o2.hashCode()
- it does not throw an exception
- Contracts over Object.clone():
- it does not throw an exception, including CloneNotSupportedException
- Contracts over Object.toString():
- it does not throw an exception
- it does not return null
- Contracts over Comparable.compareTo() and Comparator.compare():
- Reflexivity: o.compareTo(o) == 0 (implied by anti-symmetry)
- Anti-symmetry: sgn(o1.compareTo(o2)) == -sgn(o2.compareTo(o1))
- Transitivity: o1.compareTo(o2)>0 && o2.compareTo(o3)>0 ⇒ o1.compareTo(o3)>0
- Substitutability of equals: x.compareTo(y)==0 ⇒ sgn(x.compareTo(z)) == sgn(y.compareTo(z))
- Consistency with equals(): (x.compareTo(y)==0) == x.equals(y) (this contract can be disabled)
- it does not throw an exception
- Contracts over checkRep() (that is, any nullary method annotated with @CheckRep):
- it does not throw an exception
- if its return type is boolean, it returns true
- Contracts over Object.equals():
Violation of any of these contracts is highly likely to indicate an error.